 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphical Object Detection in Document Images
Paper and Code

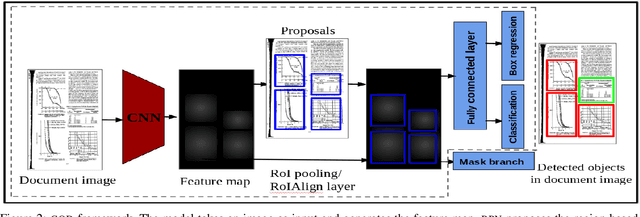


Graphical elements: particularly tables and figures contain a visual summary of the most valuable information contained in a document. Therefore, localization of such graphical objects in the document images is the initial step to understand the content of such graphical objects or document images. In this paper, we present a novel end-to-end trainable deep learning based framework to localize graphical objects in the document images called as Graphical Object Detection (GOD). Our framework is data-driven and does not require any heuristics or meta-data to locate graphical objects in the document images. The GOD explores the concept of transfer learning and domain adaptation to handle scarcity of labeled training images for graphical object detection task in the document images. Performance analysis carried out on the various public benchmark data sets: ICDAR-2013, ICDAR-POD2017,and UNLV shows that our model yields promising results as compared to state-of-the-art techniques.