 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-to-Text Generation with Dynamic Structure Pruning
Paper and Code
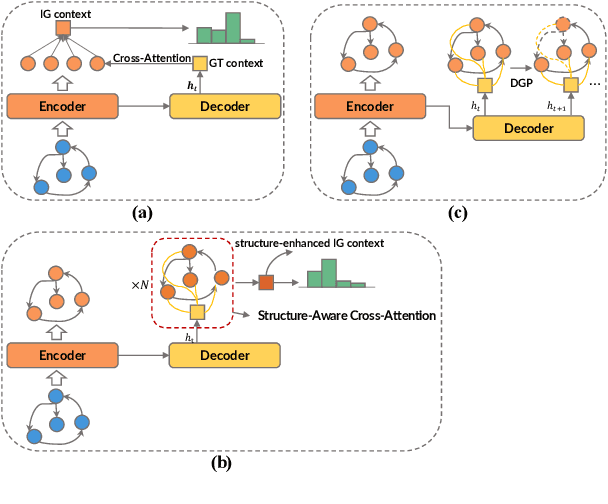
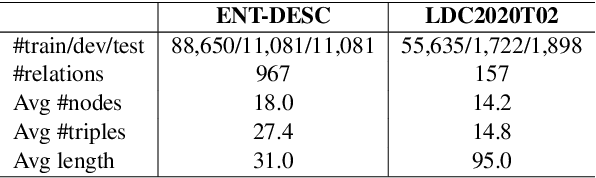
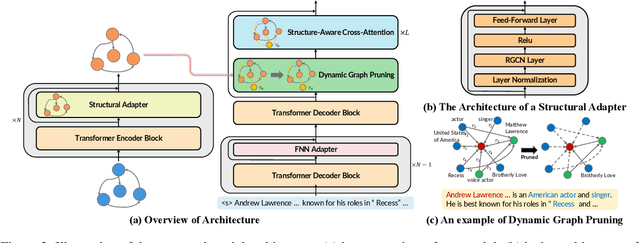
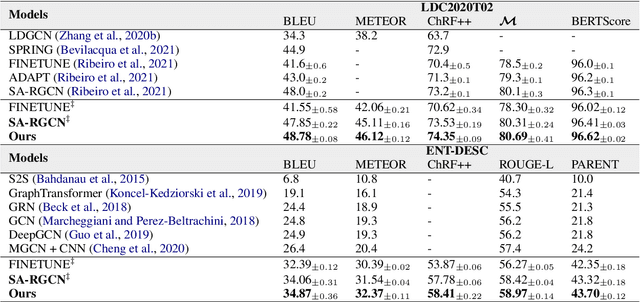
Most graph-to-text works are built on the encoder-decoder framework with cross-attention mechanism. Recent studies have shown that explicitly modeling the input graph structure can significantly improve the performance. However, the vanilla structural encoder cannot capture all specialized information in a single forward pass for all decoding steps, resulting in inaccurate semantic representations. Meanwhile, the input graph is flatted as an unordered sequence in the cross attention, ignoring the original graph structure. As a result, the obtained input graph context vector in the decoder may be flawed. To address these issues, we propose a Structure-Aware Cross-Attention (SACA) mechanism to re-encode the input graph representation conditioning on the newly generated context at each decoding step in a structure aware manner. We further adapt SACA and introduce its variant Dynamic Graph Pruning (DGP) mechanism to dynamically drop irrelevant nodes in the decoding process. We achieve new state-of-the-art results on two graph-to-text datasets, LDC2020T02 and ENT-DESC, with only minor increase on computational cost.