 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGramformer: Learning Crowd Counting via Graph-Modulated Transformer
Paper and Code


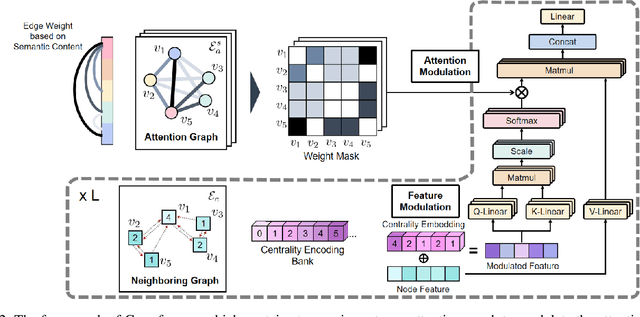

Transformer has been popular in recent crowd counting work since it breaks the limited receptive field of traditional CNNs. However, since crowd images always contain a large number of similar patches, the self-attention mechanism in Transformer tends to find a homogenized solution where the attention maps of almost all patches are identical. In this paper, we address this problem by proposing Gramformer: a graph-modulated transformer to enhance the network by adjusting the attention and input node features respectively on the basis of two different types of graphs. Firstly, an attention graph is proposed to diverse attention maps to attend to complementary information. The graph is building upon the dissimilarities between patches, modulating the attention in an anti-similarity fashion. Secondly, a feature-based centrality encoding is proposed to discover the centrality positions or importance of nodes. We encode them with a proposed centrality indices scheme to modulate the node features and similarity relationships. Extensive experiments on four challenging crowd counting datasets have validated the competitiveness of the proposed method. Code is available at {https://github.com/LoraLinH/Gramformer}.