Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoSGD: Distributed Optimization for Deep Learning with Gossip Exchange
Paper and Code
Apr 04, 2018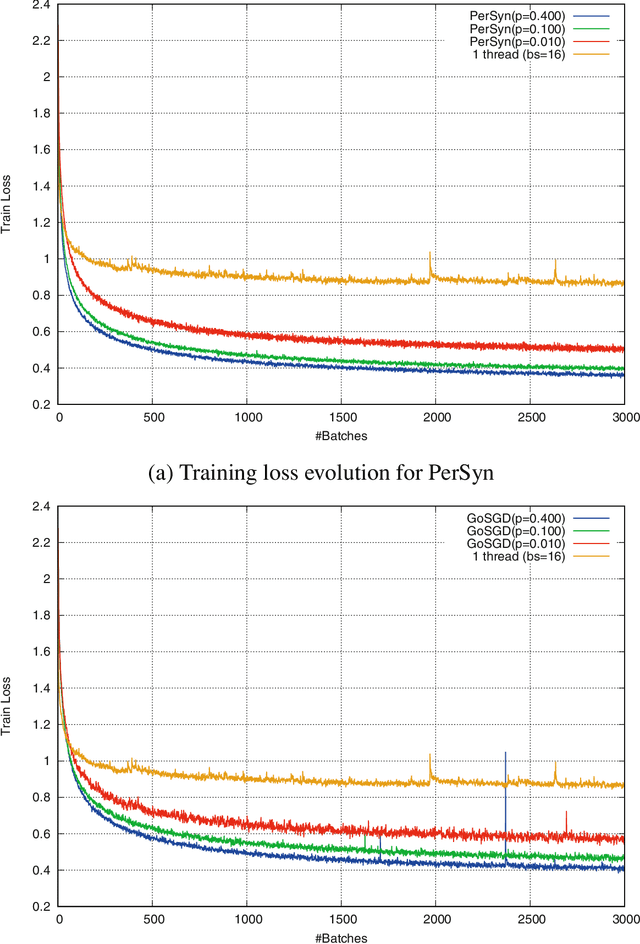
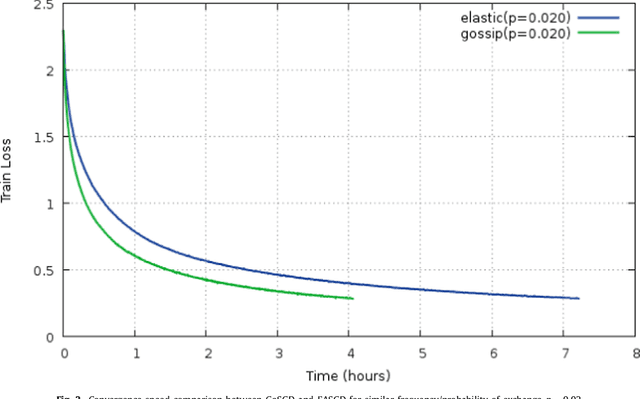
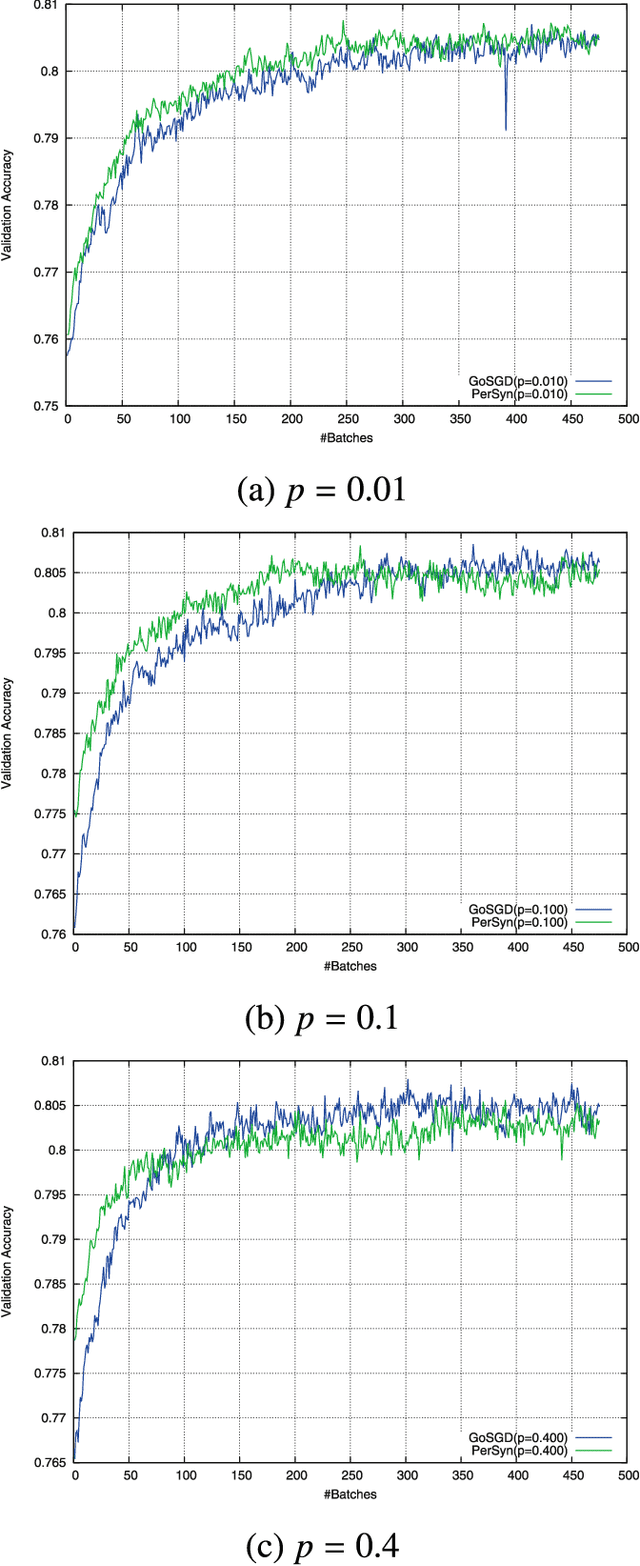
We address the issue of speeding up the training of convolutional neural networks by studying a distributed method adapted to stochastic gradient descent. Our parallel optimization setup uses several threads, each applying individual gradient descents on a local variable. We propose a new way of sharing information between different threads based on gossip algorithms that show good consensus convergence properties. Our method called GoSGD has the advantage to be fully asynchronous and decentralized.
View paper on