 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGOALS: Gradient-Only Approximations for Line Searches Towards Robust and Consistent Training of Deep Neural Networks
Paper and Code
May 23, 2021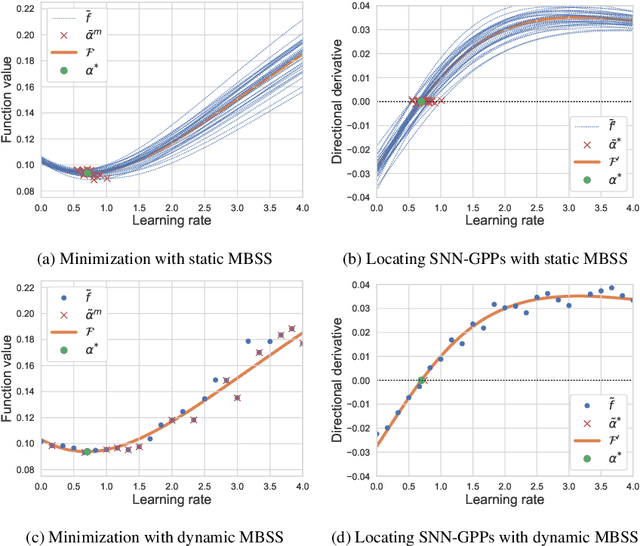

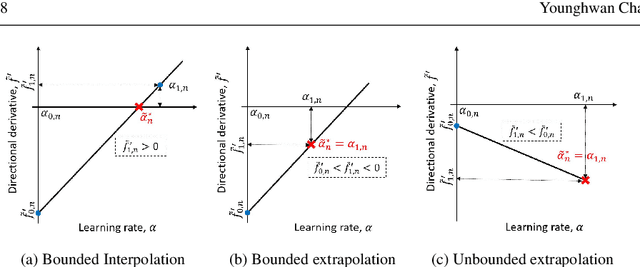

Mini-batch sub-sampling (MBSS) is favored in deep neural network training to reduce the computational cost. Still, it introduces an inherent sampling error, making the selection of appropriate learning rates challenging. The sampling errors can manifest either as a bias or variances in a line search. Dynamic MBSS re-samples a mini-batch at every function evaluation. Hence, dynamic MBSS results in point-wise discontinuous loss functions with smaller bias but larger variance than static sampled loss functions. However, dynamic MBSS has the advantage of having larger data throughput during training but requires the complexity regarding discontinuities to be resolved. This study extends the gradient-only surrogate (GOS), a line search method using quadratic approximation models built with only directional derivative information, for dynamic MBSS loss functions. We propose a gradient-only approximation line search (GOALS) with strong convergence characteristics with defined optimality criterion. We investigate GOALS's performance by applying it on various optimizers that include SGD, RMSprop and Adam on ResNet-18 and EfficientNetB0. We also compare GOALS's against the other existing learning rate methods. We quantify both the best performing and most robust algorithms. For the latter, we introduce a relative robust criterion that allows us to quantify the difference between an algorithm and the best performing algorithm for a given problem. The results show that training a model with the recommended learning rate for a class of search directions helps to reduce the model errors in multimodal cases.