 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGo-tuning: Improving Zero-shot Learning Abilities of Smaller Language Models
Paper and Code
Dec 20, 2022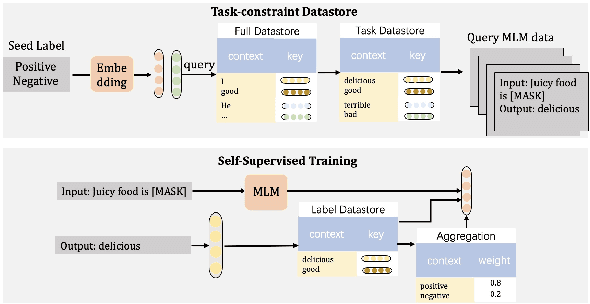


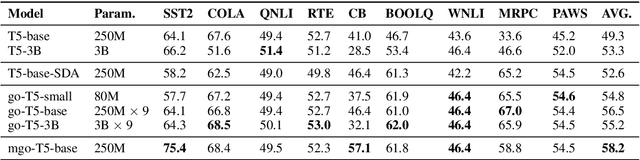
With increasing scale, large language models demonstrate both quantitative improvement and new qualitative capabilities, especially as zero-shot learners, like GPT-3. However, these results rely heavily on delicate prompt design and large computation. In this work, we explore whether the strong zero-shot ability could be achieved at a smaller model scale without any external supervised data. To achieve this goal, we revisit masked language modeling and present a geometry-guided self-supervised learning method (Go-tuningfor short) by taking a small number of task-aware self-supervised data to update language models further. Experiments show that Go-tuning can enable T5-small (80M) competitive zero-shot results compared with large language models, such as T5-XL (3B). We also apply Go-tuning on multi-task settings and develop a multi-task model, mgo-T5 (250M). It can reach the average performance of OPT (175B) on 9 datasets.