 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Context Aware Convolutions for 3D Point Cloud Understanding
Paper and Code
Aug 07, 2020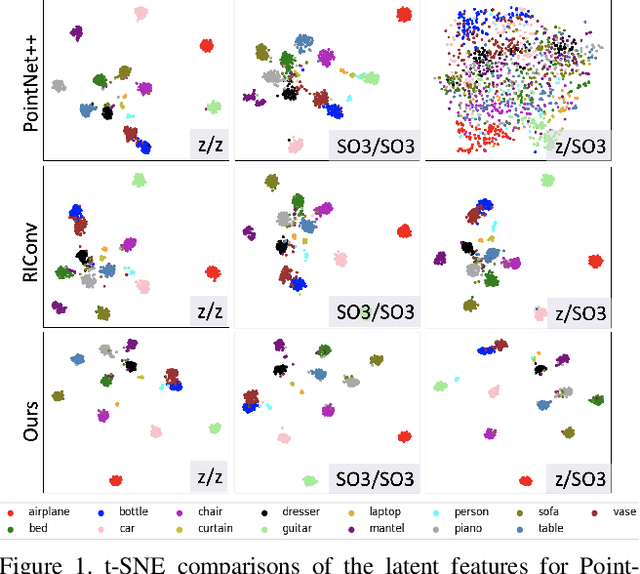
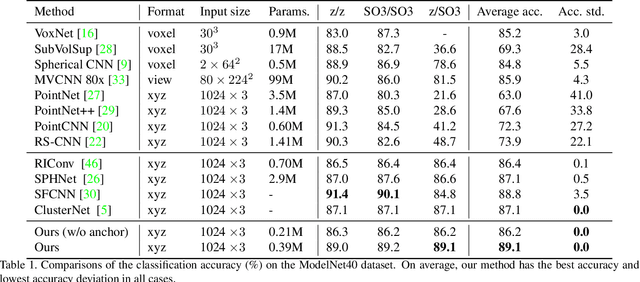
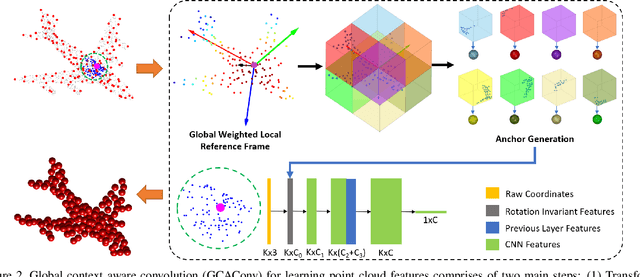

Recent advances in deep learning for 3D point clouds have shown great promises in scene understanding tasks thanks to the introduction of convolution operators to consume 3D point clouds directly in a neural network. Point cloud data, however, could have arbitrary rotations, especially those acquired from 3D scanning. Recent works show that it is possible to design point cloud convolutions with rotation invariance property, but such methods generally do not perform as well as translation-invariant only convolution. We found that a key reason is that compared to point coordinates, rotation-invariant features consumed by point cloud convolution are not as distinctive. To address this problem, we propose a novel convolution operator that enhances feature distinction by integrating global context information from the input point cloud to the convolution. To this end, a globally weighted local reference frame is constructed in each point neighborhood in which the local point set is decomposed into bins. Anchor points are generated in each bin to represent global shape features. A convolution can then be performed to transform the points and anchor features into final rotation-invariant features. We conduct several experiments on point cloud classification, part segmentation, shape retrieval, and normals estimation to evaluate our convolution, which achieves state-of-the-art accuracy under challenging rotations.