 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLISTER: Generalization based Data Subset Selection for Efficient and Robust Learning
Paper and Code


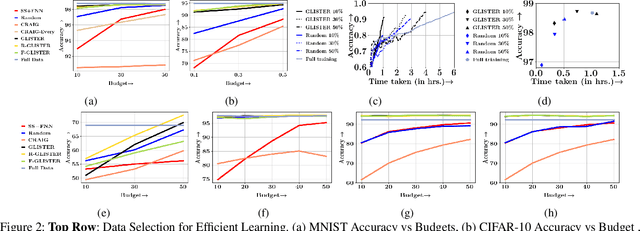
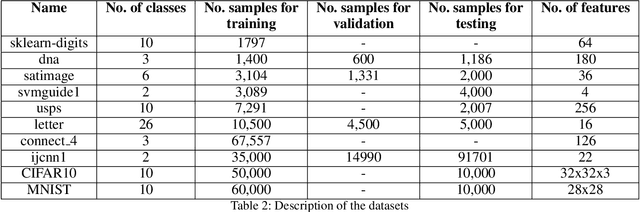
Large scale machine learning and deep models are extremely data-hungry. Unfortunately, obtaining large amounts of labeled data is expensive, and training state-of-the-art models (with hyperparameter tuning) requires significant computing resources and time. Secondly, real-world data is noisy and imbalanced. As a result, several recent papers try to make the training process more efficient and robust. However, most existing work either focuses on robustness or efficiency, but not both. In this work, we introduce Glister, a GeneraLIzation based data Subset selecTion for Efficient and Robust learning framework. We formulate Glister as a mixed discrete-continuous bi-level optimization problem to select a subset of the training data, which maximizes the log-likelihood on a held-out validation set. Next, we propose an iterative online algorithm Glister-Online, which performs data selection iteratively along with the parameter updates and can be applied to any loss-based learning algorithm. We then show that for a rich class of loss functions including cross-entropy, hinge-loss, squared-loss, and logistic-loss, the inner discrete data selection is an instance of (weakly) submodular optimization, and we analyze conditions for which Glister-Online reduces the validation loss and converges. Finally, we propose Glister-Active, an extension to batch active learning, and we empirically demonstrate the performance of Glister on a wide range of tasks including, (a) data selection to reduce training time, (b) robust learning under label noise and imbalance settings, and (c) batch-active learning with several deep and shallow models. We show that our framework improves upon state of the art both in efficiency and accuracy (in cases (a) and (c)) and is more efficient compared to other state-of-the-art robust learning algorithms in case (b).