 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGFF: Gated Fully Fusion for Semantic Segmentation
Paper and Code
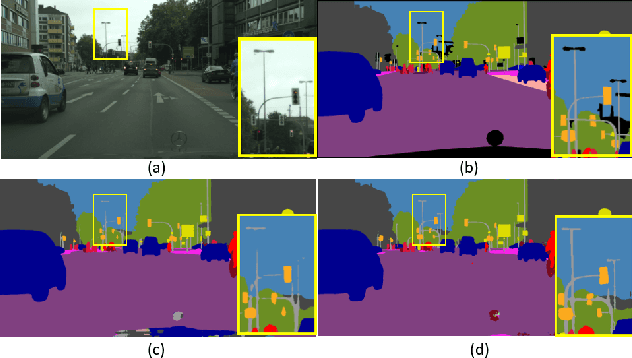
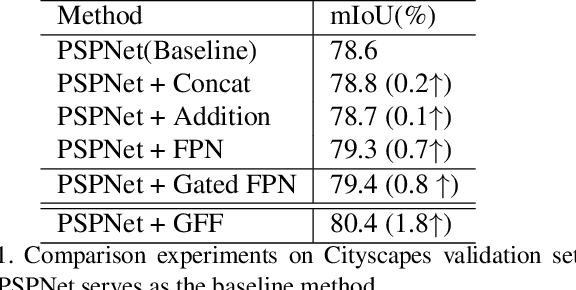
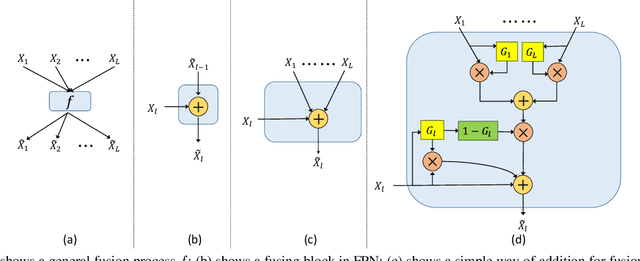
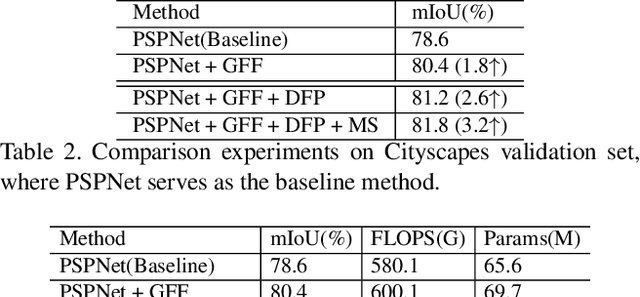
Semantic segmentation generates comprehensive understanding of scenes at a semantic level through densely predicting the category for each pixel. High-level features from Deep Convolutional Neural Networks already demonstrate their effectiveness in semantic segmentation tasks, however the coarse resolution of high-level features often leads to inferior results for small/thin objects where detailed information is important but missing. It is natural to consider importing low level features to compensate the lost detailed information in high level representations. Unfortunately, simply combining multi-level features is less effective due to the semantic gap existing among them. In this paper, we propose a new architecture, named Gated Fully Fusion(GFF), to selectively fuse features from multiple levels using gates in a fully connected way. Specifically, features at each level are enhanced by higher-level features with stronger semantics and lower-level features with more details, and gates are used to control the propagation of useful information which significantly reduces the noises during fusion. We achieve the state of the art results on two challenging scene understanding datasets, i.e., 82.3% mIoU on Cityscapes test set and 45.3% mIoU on ADE20K validation set. Codes and the trained models will be made publicly available.