 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative vs. Discriminative modeling under the lens of uncertainty quantification
Paper and Code
Jun 13, 2024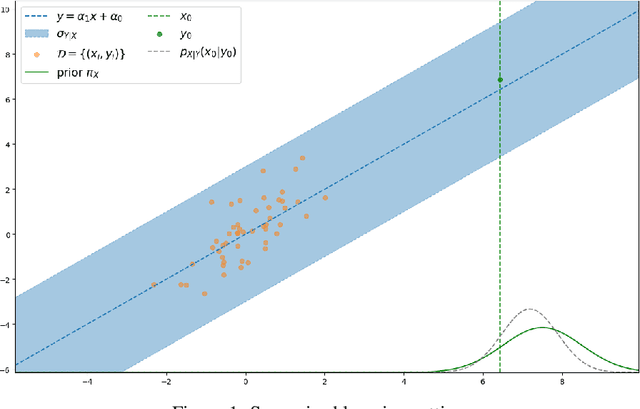



Learning a parametric model from a given dataset indeed enables to capture intrinsic dependencies between random variables via a parametric conditional probability distribution and in turn predict the value of a label variable given observed variables. In this paper, we undertake a comparative analysis of generative and discriminative approaches which differ in their construction and the structure of the underlying inference problem. Our objective is to compare the ability of both approaches to leverage information from various sources in an epistemic uncertainty aware inference via the posterior predictive distribution. We assess the role of a prior distribution, explicit in the generative case and implicit in the discriminative case, leading to a discussion about discriminative models suffering from imbalanced dataset. We next examine the double role played by the observed variables in the generative case, and discuss the compatibility of both approaches with semi-supervised learning. We also provide with practical insights and we examine how the modeling choice impacts the sampling from the posterior predictive distribution. With regard to this, we propose a general sampling scheme enabling supervised learning for both approaches, as well as semi-supervised learning when compatible with the considered modeling approach. Throughout this paper, we illustrate our arguments and conclusions using the example of affine regression, and validate our comparative analysis through classification simulations using neural network based models.