 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Pre-trained Ranking Model with Over-parameterization at Web-Scale (Extended Abstract)
Paper and Code
Sep 25, 2024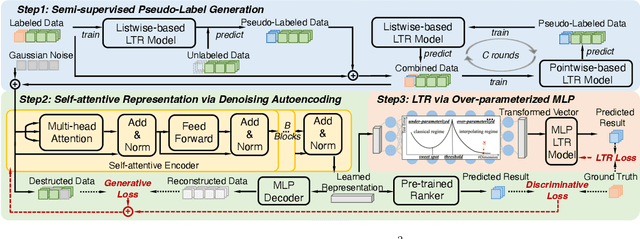
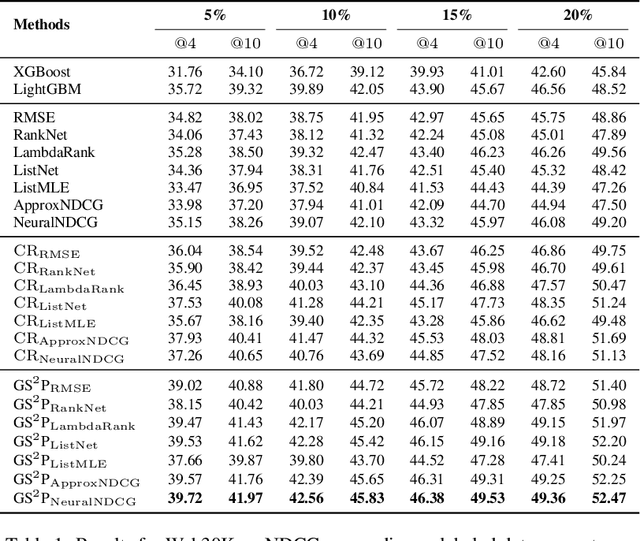
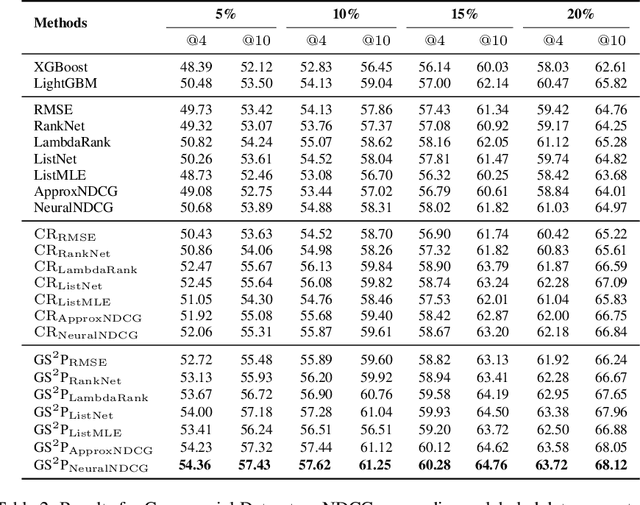
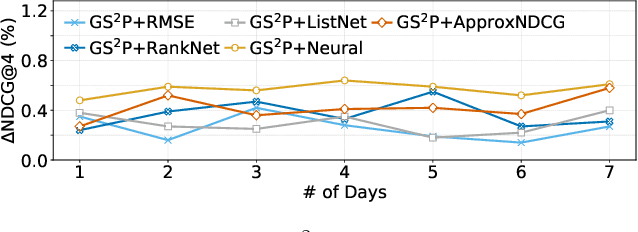
Learning to rank (LTR) is widely employed in web searches to prioritize pertinent webpages from retrieved content based on input queries. However, traditional LTR models encounter two principal obstacles that lead to suboptimal performance: (1) the lack of well-annotated query-webpage pairs with ranking scores covering a diverse range of search query popularities, which hampers their ability to address queries across the popularity spectrum, and (2) inadequately trained models that fail to induce generalized representations for LTR, resulting in overfitting. To address these challenges, we propose a \emph{\uline{G}enerative \uline{S}emi-\uline{S}upervised \uline{P}re-trained} (GS2P) LTR model. We conduct extensive offline experiments on both a publicly available dataset and a real-world dataset collected from a large-scale search engine. Furthermore, we deploy GS2P in a large-scale web search engine with realistic traffic, where we observe significant improvements in the real-world application.