Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Models for Pose Transfer
Paper and Code
Jun 24, 2018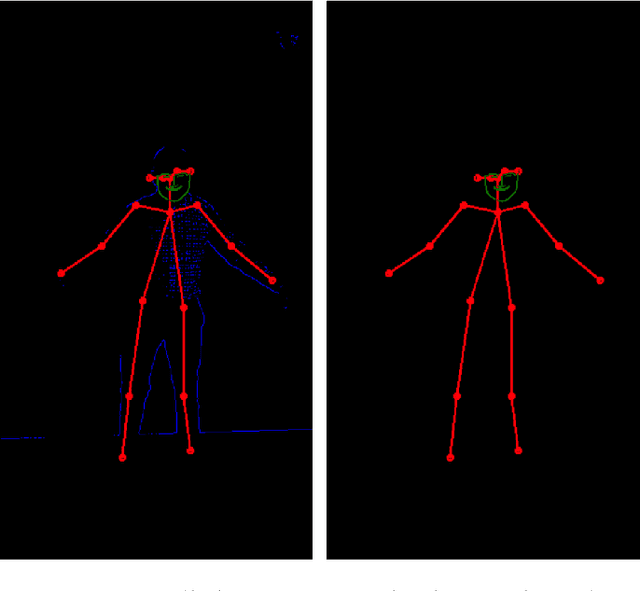


We investigate nearest neighbor and generative models for transferring pose between persons. We take in a video of one person performing a sequence of actions and attempt to generate a video of another person performing the same actions. Our generative model (pix2pix) outperforms k-NN at both generating corresponding frames and generalizing outside the demonstrated action set. Our most salient contribution is determining a pipeline (pose detection, face detection, k-NN based pairing) that is effective at perform-ing the desired task. We also detail several iterative improvements and failure modes.
View paper on