 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Modelling of BRDF Textures from Flash Images
Paper and Code


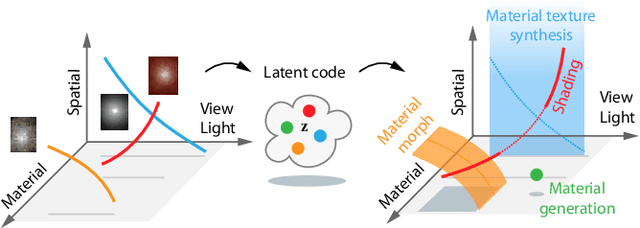

We learn a latent space for easy capture, semantic editing, consistent interpolation, and efficient reproduction of visual material appearance. When users provide a photo of a stationary natural material captured under flash light illumination, it is converted in milliseconds into a latent material code. In a second step, conditioned on the material code, our method, again in milliseconds, produces an infinite and diverse spatial field of BRDF model parameters (diffuse albedo, specular albedo, roughness, normals) that allows rendering in complex scenes and illuminations, matching the appearance of the input picture. Technically, we jointly embed all flash images into a latent space using a convolutional encoder, and -- conditioned on these latent codes -- convert random spatial fields into fields of BRDF parameters using a convolutional neural network (CNN). We condition these BRDF parameters to match the visual characteristics (statistics and spectra of visual features) of the input under matching light. A user study confirms that the semantics of the latent material space agree with user expectations and compares our approach favorably to previous work.