 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Language Models Potential for Requirement Engineering Applications: Insights into Current Strengths and Limitations
Paper and Code
Dec 01, 2024

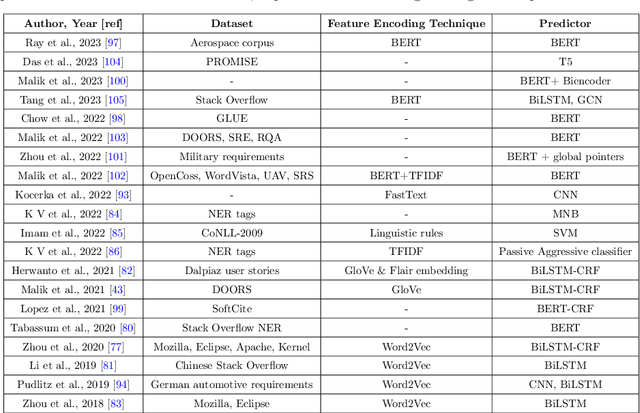
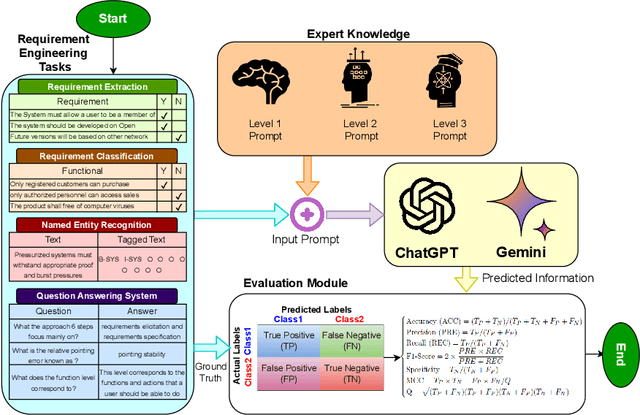
Traditional language models have been extensively evaluated for software engineering domain, however the potential of ChatGPT and Gemini have not been fully explored. To fulfill this gap, the paper in hand presents a comprehensive case study to investigate the potential of both language models for development of diverse types of requirement engineering applications. It deeply explores impact of varying levels of expert knowledge prompts on the prediction accuracies of both language models. Across 4 different public benchmark datasets of requirement engineering tasks, it compares performance of both language models with existing task specific machine/deep learning predictors and traditional language models. Specifically, the paper utilizes 4 benchmark datasets; Pure (7,445 samples, requirements extraction),PROMISE (622 samples, requirements classification), REQuestA (300 question answer (QA) pairs) and Aerospace datasets (6347 words, requirements NER tagging). Our experiments reveal that, in comparison to ChatGPT, Gemini requires more careful prompt engineering to provide accurate predictions. Moreover, across requirement extraction benchmark dataset the state-of-the-art F1-score is 0.86 while ChatGPT and Gemini achieved 0.76 and 0.77,respectively. The State-of-the-art F1-score on requirements classification dataset is 0.96 and both language models 0.78. In name entity recognition (NER) task the state-of-the-art F1-score is 0.92 and ChatGPT managed to produce 0.36, and Gemini 0.25. Similarly, across question answering dataset the state-of-the-art F1-score is 0.90 and ChatGPT and Gemini managed to produce 0.91 and 0.88 respectively. Our experiments show that Gemini requires more precise prompt engineering than ChatGPT. Except for question-answering, both models under-perform compared to current state-of-the-art predictors across other tasks.