 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Imagination Elevates Machine Translation
Paper and Code
Sep 21, 2020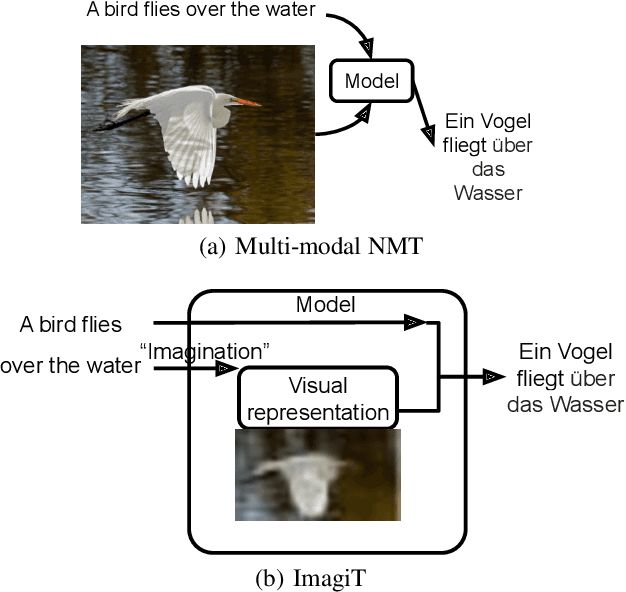



There are thousands of languages on earth, but visual perception is shared among peoples. Existing multimodal neural machine translation (MNMT) methods achieve knowledge transfer by enforcing one encoder to learn shared representation across textual and visual modalities. However, the training and inference process heavily relies on well-aligned bilingual sentence - image triplets as input, which are often limited in quantity. In this paper, we hypothesize that visual imagination via synthesizing visual representation from source text could help the neural model map two languages with different symbols, thus helps the translation task. Our proposed end-to-end imagination-based machine translation model (ImagiT) first learns to generate semantic-consistent visual representation from source sentence, and then generate target sentence based on both text representation and imagined visual representation. Experiments demonstrate that our translation model benefits from visual imagination and significantly outperforms the text-only neural machine translation (NMT) baseline. We also conduct analyzing experiments, and the results show that imagination can help fill in missing information when performing the degradation strategy.