 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Emotion Cause Explanation in Multimodal Conversations
Paper and Code
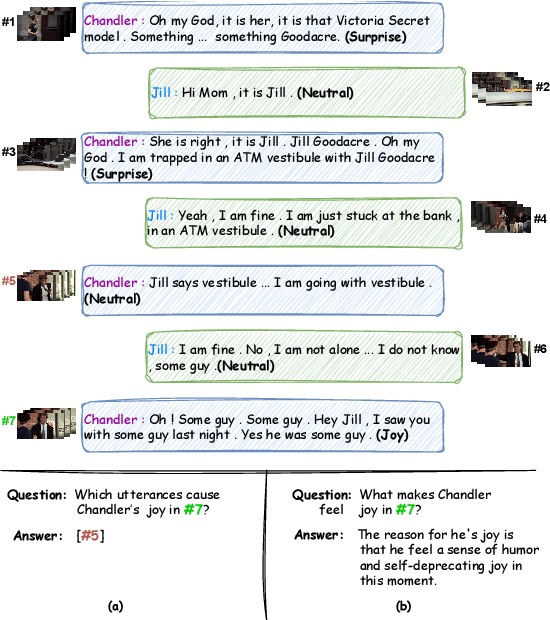


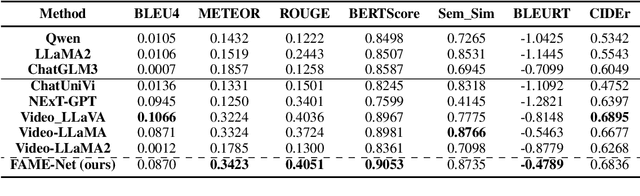
Multimodal conversation, a crucial form of human communication, carries rich emotional content, making the exploration of the causes of emotions within it a research endeavor of significant importance. However, existing research on the causes of emotions typically uses clause selection methods to locate the reason utterance, without providing a detailed explanation of the emotional causes. In this paper, we propose a new task, \textbf{M}ultimodal \textbf{C}onversation \textbf{E}motion \textbf{C}ause \textbf{E}xplanation (MCECE), aiming to generate a detailed explanation of the emotional cause to the target utterance within a multimodal conversation scenario. Building upon the MELD dataset, we develop a new dataset (ECEM) that integrates video clips with detailed explanations of character emotions, facilitating an in-depth examination of the causal factors behind emotional expressions in multimodal conversations.A novel approach, FAME-Net, is further proposed, that harnesses the power of Large Language Models (LLMs) to analyze visual data and accurately interpret the emotions conveyed through facial expressions in videos. By exploiting the contagion effect of facial emotions, FAME-Net effectively captures the emotional causes of individuals engaged in conversations. Our experimental results on the newly constructed dataset show that FAME-Net significantly outperforms several excellent large language model baselines. Code and dataset are available at \url{https://github.com/3222345200/ECEMdataset.git}