 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative adversarial network-based glottal waveform model for statistical parametric speech synthesis
Paper and Code
Mar 14, 2019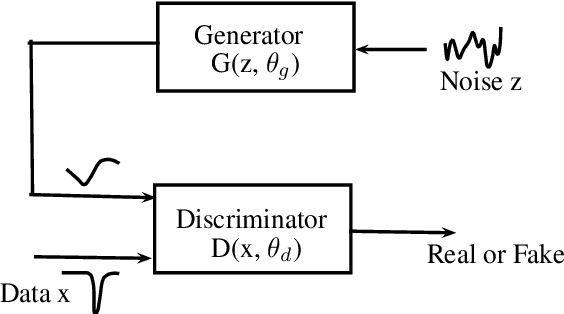

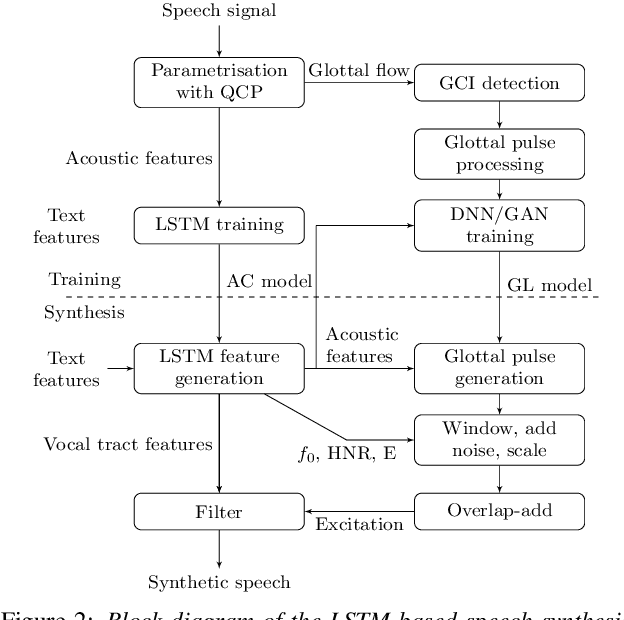

Recent studies have shown that text-to-speech synthesis quality can be improved by using glottal vocoding. This refers to vocoders that parameterize speech into two parts, the glottal excitation and vocal tract, that occur in the human speech production apparatus. Current glottal vocoders generate the glottal excitation waveform by using deep neural networks (DNNs). However, the squared error-based training of the present glottal excitation models is limited to generating conditional average waveforms, which fails to capture the stochastic variation of the waveforms. As a result, shaped noise is added as post-processing. In this study, we propose a new method for predicting glottal waveforms by generative adversarial networks (GANs). GANs are generative models that aim to embed the data distribution in a latent space, enabling generation of new instances very similar to the original by randomly sampling the latent distribution. The glottal pulses generated by GANs show a stochastic component similar to natural glottal pulses. In our experiments, we compare synthetic speech generated using glottal waveforms produced by both DNNs and GANs. The results show that the newly proposed GANs achieve synthesis quality comparable to that of widely-used DNNs, without using an additive noise component.