 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating unseen complex scenes: are we there yet?
Paper and Code
Dec 07, 2020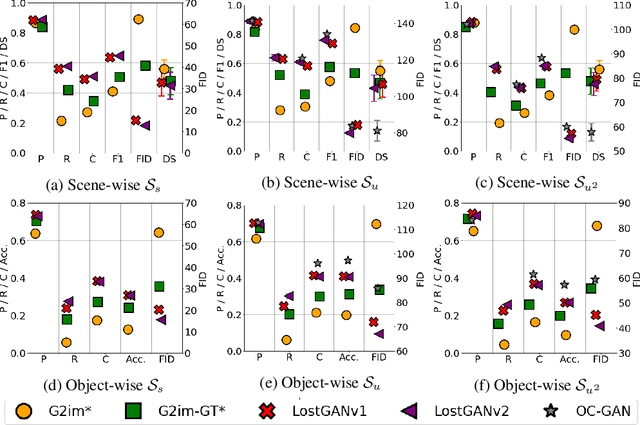
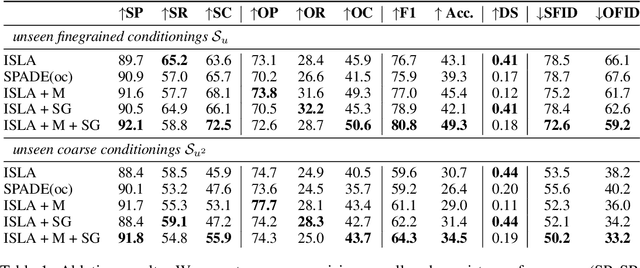
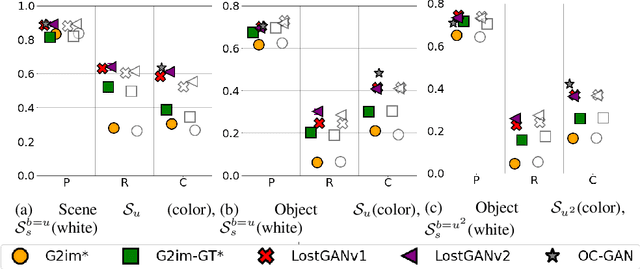

Although recent complex scene conditional generation models generate increasingly appealing scenes, it is very hard to assess which models perform better and why. This is often due to models being trained to fit different data splits, and defining their own experimental setups. In this paper, we propose a methodology to compare complex scene conditional generation models, and provide an in-depth analysis that assesses the ability of each model to (1) fit the training distribution and hence perform well on seen conditionings, (2) to generalize to unseen conditionings composed of seen object combinations, and (3) generalize to unseen conditionings composed of unseen object combinations. As a result, we observe that recent methods are able to generate recognizable scenes given seen conditionings, and exploit compositionality to generalize to unseen conditionings with seen object combinations. However, all methods suffer from noticeable image quality degradation when asked to generate images from conditionings composed of unseen object combinations. Moreover, through our analysis, we identify the advantages of different pipeline components, and find that (1) encouraging compositionality through instance-wise spatial conditioning normalizations increases robustness to both types of unseen conditionings, (2) using semantically aware losses such as the scene-graph perceptual similarity helps improve some dimensions of the generation process, and (3) enhancing the quality of generated masks and the quality of the individual objects are crucial steps to improve robustness to both types of unseen conditionings.