 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Unrestricted Adversarial Examples via Three Parameters
Paper and Code
Mar 13, 2021
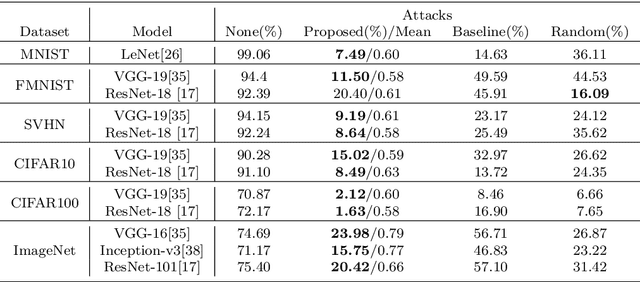


Deep neural networks have been shown to be vulnerable to adversarial examples deliberately constructed to misclassify victim models. As most adversarial examples have restricted their perturbations to $L_{p}$-norm, existing defense methods have focused on these types of perturbations and less attention has been paid to unrestricted adversarial examples; which can create more realistic attacks, able to deceive models without affecting human predictions. To address this problem, the proposed adversarial attack generates an unrestricted adversarial example with a limited number of parameters. The attack selects three points on the input image and based on their locations transforms the image into an adversarial example. By limiting the range of movement and location of these three points and using a discriminatory network, the proposed unrestricted adversarial example preserves the image appearance. Experimental results show that the proposed adversarial examples obtain an average success rate of 93.5% in terms of human evaluation on the MNIST and SVHN datasets. It also reduces the model accuracy by an average of 73% on six datasets MNIST, FMNIST, SVHN, CIFAR10, CIFAR100, and ImageNet. It should be noted that, in the case of attacks, lower accuracy in the victim model denotes a more successful attack. The adversarial train of the attack also improves model robustness against a randomly transformed image.