 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Synthetic Free-text Medical Records with Low Re-identification Risk using Masked Language Modeling
Paper and Code
Sep 17, 2024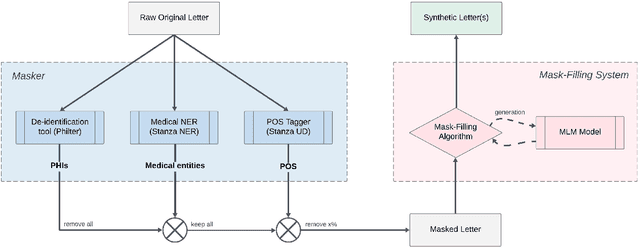
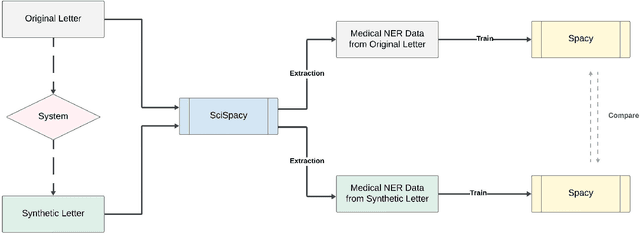

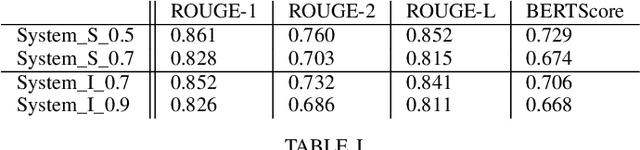
In this paper, we present a system that generates synthetic free-text medical records, such as discharge summaries, admission notes and doctor correspondences, using Masked Language Modeling (MLM). Our system is designed to preserve the critical information of the records while introducing significant diversity and minimizing re-identification risk. The system incorporates a de-identification component that uses Philter to mask Protected Health Information (PHI), followed by a Medical Entity Recognition (NER) model to retain key medical information. We explore various masking ratios and mask-filling techniques to balance the trade-off between diversity and fidelity in the synthetic outputs without affecting overall readability. Our results demonstrate that the system can produce high-quality synthetic data with significant diversity while achieving a HIPAA-compliant PHI recall rate of 0.96 and a low re-identification risk of 0.035. Furthermore, downstream evaluations using a NER task reveal that the synthetic data can be effectively used to train models with performance comparable to those trained on real data. The flexibility of the system allows it to be adapted for specific use cases, making it a valuable tool for privacy-preserving data generation in medical research and healthcare applications.