Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating a Diverse Set of High-Quality Clusterings
Paper and Code
Jul 29, 2011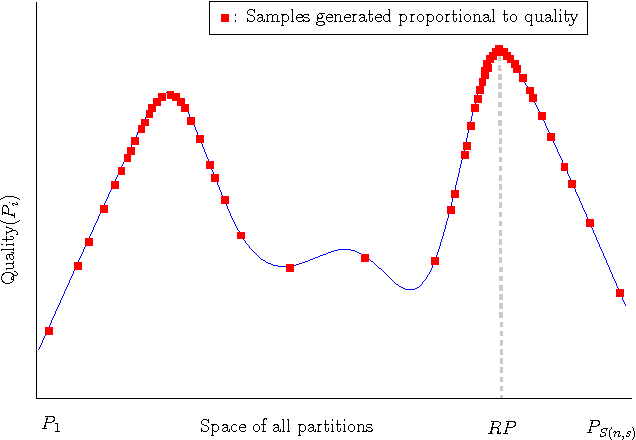
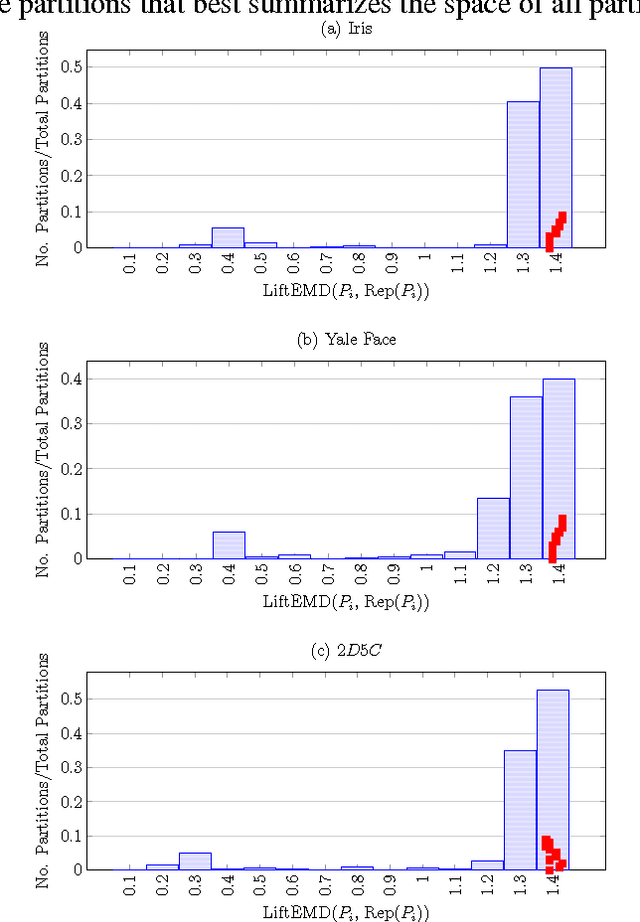
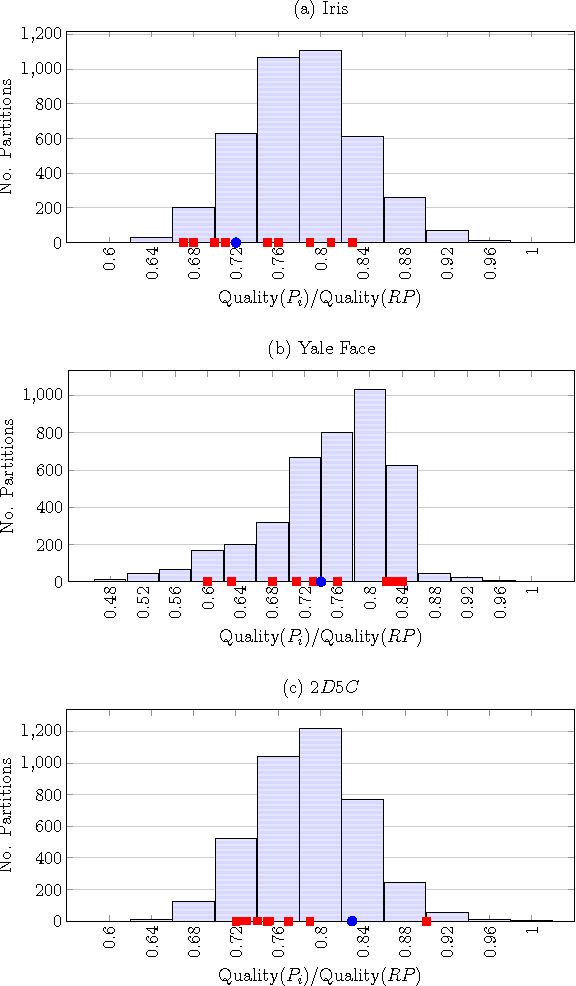
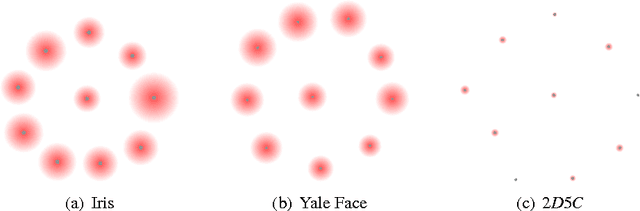
We provide a new framework for generating multiple good quality partitions (clusterings) of a single data set. Our approach decomposes this problem into two components, generating many high-quality partitions, and then grouping these partitions to obtain k representatives. The decomposition makes the approach extremely modular and allows us to optimize various criteria that control the choice of representative partitions.
* 12 Pages, 5 Figures, 2nd MultiClust Workshop at ECML PKDD 2011
View paper on