 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Linear Models for Aggregated Data
Paper and Code
May 14, 2016

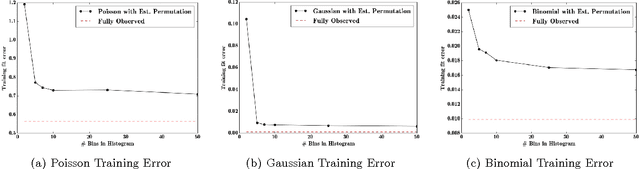
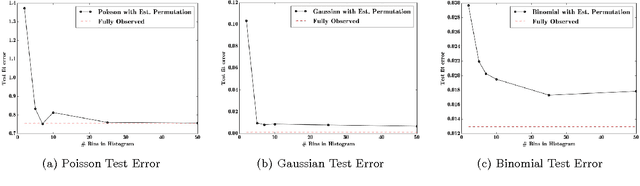
Databases in domains such as healthcare are routinely released to the public in aggregated form. Unfortunately, naive modeling with aggregated data may significantly diminish the accuracy of inferences at the individual level. This paper addresses the scenario where features are provided at the individual level, but the target variables are only available as histogram aggregates or order statistics. We consider a limiting case of generalized linear modeling when the target variables are only known up to permutation, and explore how this relates to permutation testing; a standard technique for assessing statistical dependency. Based on this relationship, we propose a simple algorithm to estimate the model parameters and individual level inferences via alternating imputation and standard generalized linear model fitting. Our results suggest the effectiveness of the proposed approach when, in the original data, permutation testing accurately ascertains the veracity of the linear relationship. The framework is extended to general histogram data with larger bins - with order statistics such as the median as a limiting case. Our experimental results on simulated data and aggregated healthcare data suggest a diminishing returns property with respect to the granularity of the histogram - when a linear relationship holds in the original data, the targets can be predicted accurately given relatively coarse histograms.