 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Few-Shot Semantic Segmentation: All You Need is Fine-Tuning
Paper and Code
Dec 21, 2021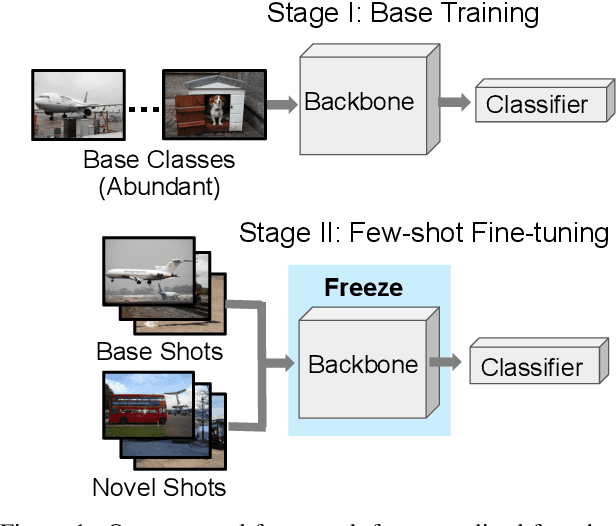
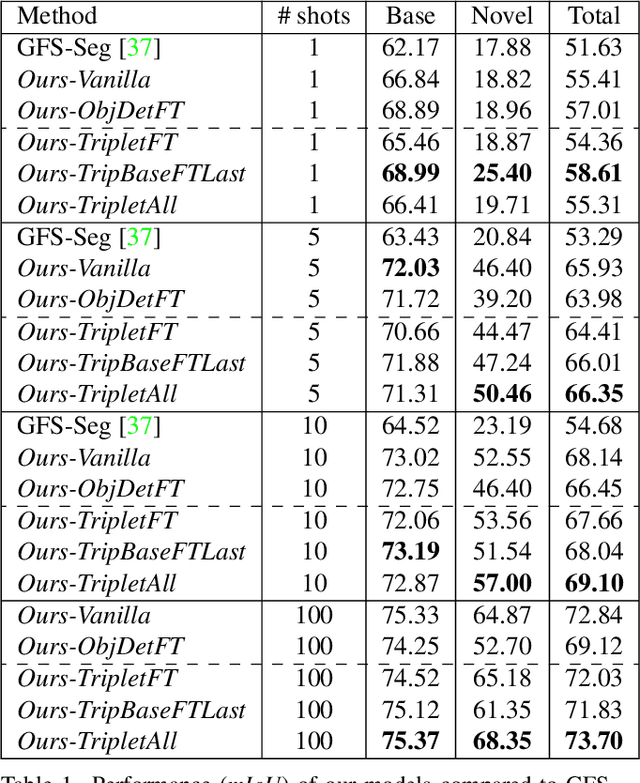
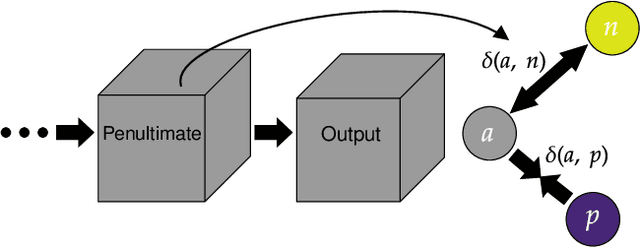
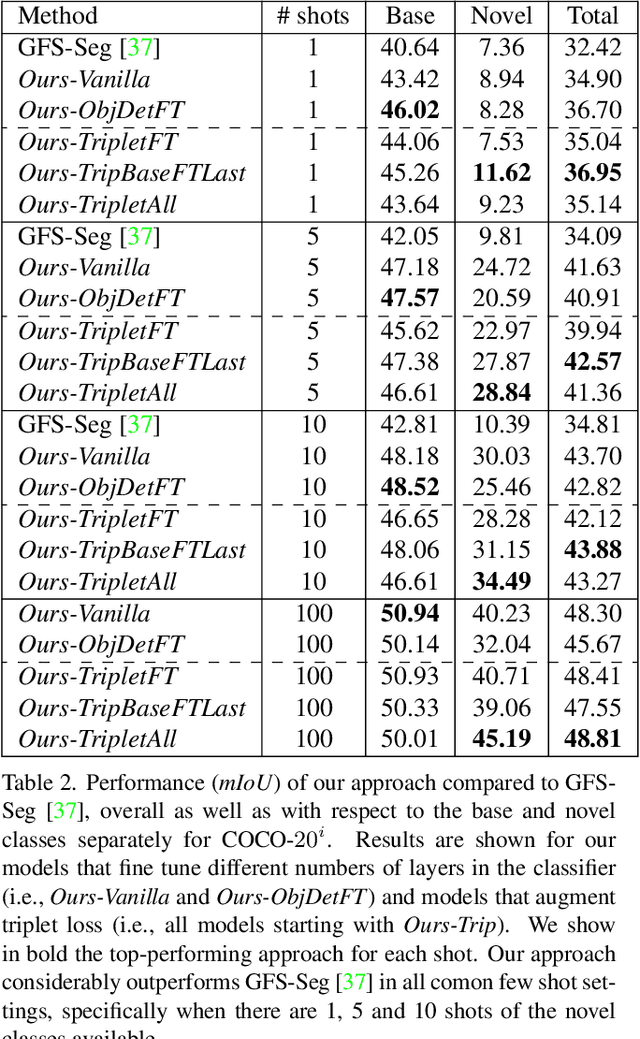
Generalized few-shot semantic segmentation was introduced to move beyond only evaluating few-shot segmentation models on novel classes to include testing their ability to remember base classes. While all approaches currently are based on meta-learning, they perform poorly and saturate in learning after observing only a few shots. We propose the first fine-tuning solution, and demonstrate that it addresses the saturation problem while achieving state-of-art results on two datasets, PASCAL-$5^i$ and COCO-$20^i$. We also show it outperforms existing methods whether fine-tuning multiple final layers or only the final layer. Finally, we present a triplet loss regularization that shows how to redistribute the balance of performance between novel and base categories so that there is a smaller gap between them.