 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Bounds of Surrogate Policies for Combinatorial Optimization Problems
Paper and Code
Jul 24, 2024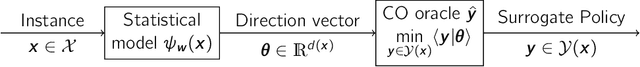
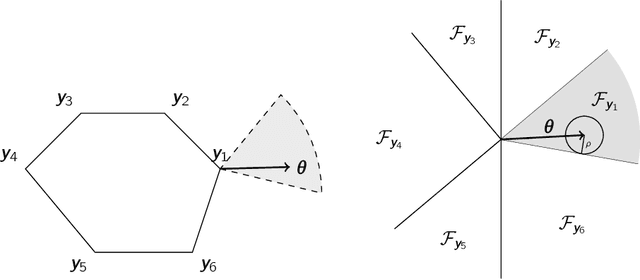
A recent stream of structured learning approaches has improved the practical state of the art for a range of combinatorial optimization problems with complex objectives encountered in operations research. Such approaches train policies that chain a statistical model with a surrogate combinatorial optimization oracle to map any instance of the problem to a feasible solution. The key idea is to exploit the statistical distribution over instances instead of dealing with instances separately. However learning such policies by risk minimization is challenging because the empirical risk is piecewise constant in the parameters, and few theoretical guarantees have been provided so far. In this article, we investigate methods that smooth the risk by perturbing the policy, which eases optimization and improves generalization. Our main contribution is a generalization bound that controls the perturbation bias, the statistical learning error, and the optimization error. Our analysis relies on the introduction of a uniform weak property, which captures and quantifies the interplay of the statistical model and the surrogate combinatorial optimization oracle. This property holds under mild assumptions on the statistical model, the surrogate optimization, and the instance data distribution. We illustrate the result on a range of applications such as stochastic vehicle scheduling. In particular, such policies are relevant for contextual stochastic optimization and our results cover this case.