 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable One-shot Neural Head Avatar
Paper and Code



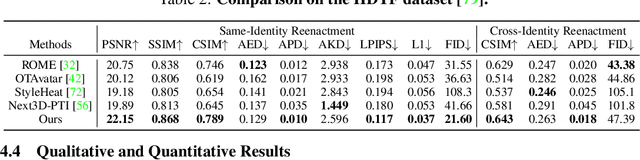
We present a method that reconstructs and animates a 3D head avatar from a single-view portrait image. Existing methods either involve time-consuming optimization for a specific person with multiple images, or they struggle to synthesize intricate appearance details beyond the facial region. To address these limitations, we propose a framework that not only generalizes to unseen identities based on a single-view image without requiring person-specific optimization, but also captures characteristic details within and beyond the face area (e.g. hairstyle, accessories, etc.). At the core of our method are three branches that produce three tri-planes representing the coarse 3D geometry, detailed appearance of a source image, as well as the expression of a target image. By applying volumetric rendering to the combination of the three tri-planes followed by a super-resolution module, our method yields a high fidelity image of the desired identity, expression and pose. Once trained, our model enables efficient 3D head avatar reconstruction and animation via a single forward pass through a network. Experiments show that the proposed approach generalizes well to unseen validation datasets, surpassing SOTA baseline methods by a large margin on head avatar reconstruction and animation.