 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGBRS: An Unified Model of Pawlak Rough Set and Neighborhood Rough Set
Paper and Code
Jan 11, 2022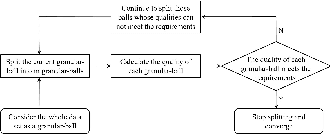
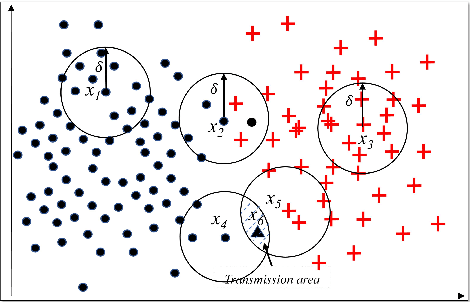
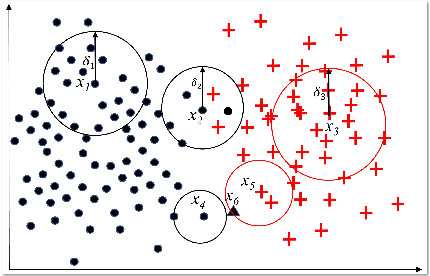
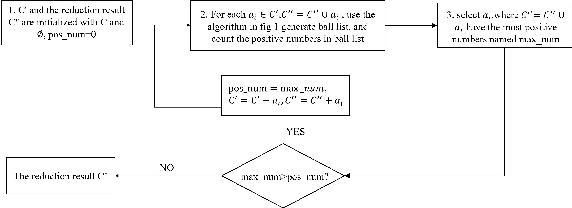
Pawlak rough set and neighborhood rough set are the two most common rough set theoretical models. Pawlawk can use equivalence classes to represent knowledge, but it cannot process continuous data; neighborhood rough sets can process continuous data, but it loses the ability of using equivalence classes to represent knowledge. To this end, this paper presents a granular-ball rough set based on the granlar-ball computing. The granular-ball rough set can simultaneously represent Pawlak rough sets, and the neighborhood rough set, so as to realize the unified representation of the two. This makes the granular-ball rough set not only can deal with continuous data, but also can use equivalence classes for knowledge representation. In addition, we propose an implementation algorithms of granular-ball rough sets. The experimental resuts on benchmark datasets demonstrate that, due to the combination of the robustness and adaptability of the granular-ball computing, the learning accuracy of the granular-ball rough set has been greatly improved compared with the Pawlak rough set and the traditional neighborhood rough set. The granular-ball rough set also outperforms nine popular or the state-of-the-art feature selection methods.