 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazeDPM: Early Integration of Gaze Information in Deformable Part Models
Paper and Code
May 21, 2015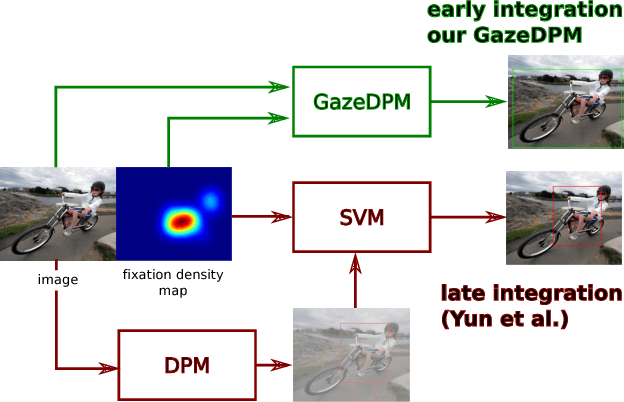
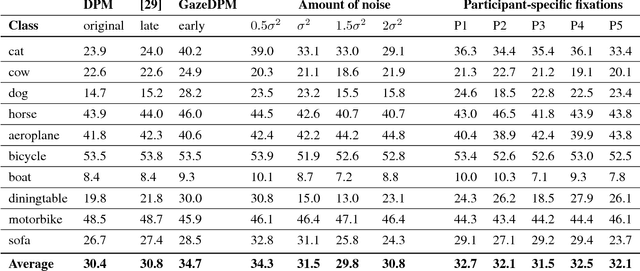

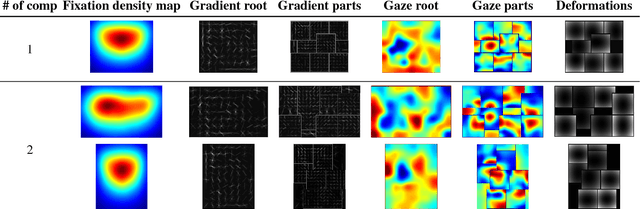
An increasing number of works explore collaborative human-computer systems in which human gaze is used to enhance computer vision systems. For object detection these efforts were so far restricted to late integration approaches that have inherent limitations, such as increased precision without increase in recall. We propose an early integration approach in a deformable part model, which constitutes a joint formulation over gaze and visual data. We show that our GazeDPM method improves over the state-of-the-art DPM baseline by 4% and a recent method for gaze-supported object detection by 3% on the public POET dataset. Our approach additionally provides introspection of the learnt models, can reveal salient image structures, and allows us to investigate the interplay between gaze attracting and repelling areas, the importance of view-specific models, as well as viewers' personal biases in gaze patterns. We finally study important practical aspects of our approach, such as the impact of using saliency maps instead of real fixations, the impact of the number of fixations, as well as robustness to gaze estimation error.