 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Mixture Clustering Using Relative Tests of Fit
Paper and Code
Oct 07, 2019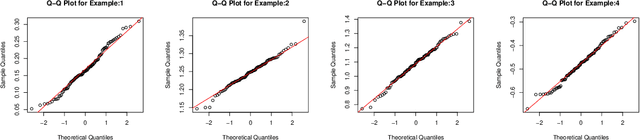
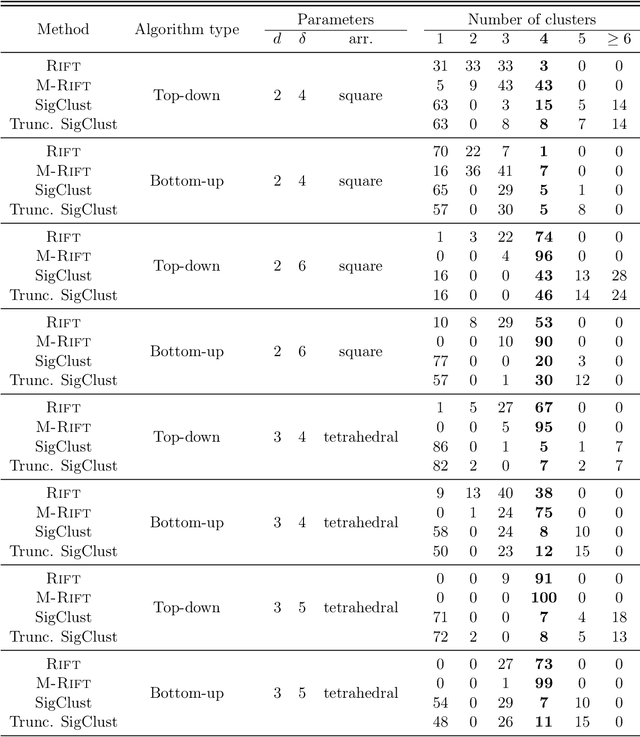
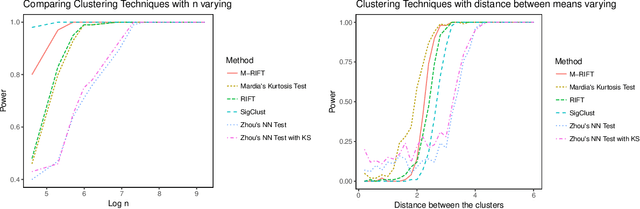
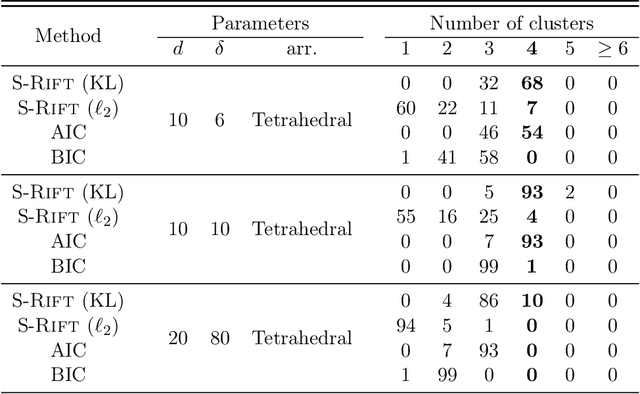
We consider clustering based on significance tests for Gaussian Mixture Models (GMMs). Our starting point is the SigClust method developed by Liu et al. (2008), which introduces a test based on the k-means objective (with k = 2) to decide whether the data should be split into two clusters. When applied recursively, this test yields a method for hierarchical clustering that is equipped with a significance guarantee. We study the limiting distribution and power of this approach in some examples and show that there are large regions of the parameter space where the power is low. We then introduce a new test based on the idea of relative fit. Unlike prior work, we test for whether a mixture of Gaussians provides a better fit relative to a single Gaussian, without assuming that either model is correct. The proposed test has a simple critical value and provides provable error control. One version of our test provides exact, finite sample control of the type I error. We show how our tests can be used for hierarchical clustering as well as in a sequential manner for model selection. We conclude with an extensive simulation study and a cluster analysis of a gene expression dataset.