 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated-Attention Architectures for Task-Oriented Language Grounding
Paper and Code

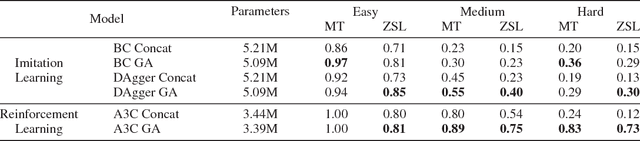
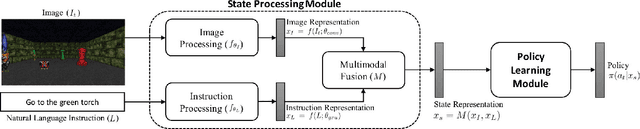
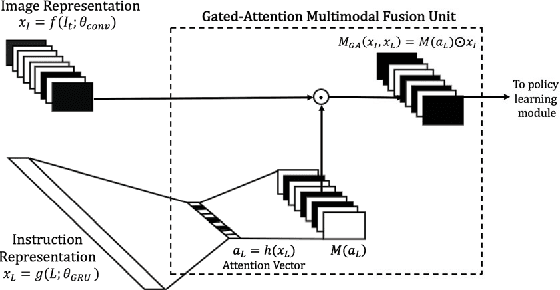
To perform tasks specified by natural language instructions, autonomous agents need to extract semantically meaningful representations of language and map it to visual elements and actions in the environment. This problem is called task-oriented language grounding. We propose an end-to-end trainable neural architecture for task-oriented language grounding in 3D environments which assumes no prior linguistic or perceptual knowledge and requires only raw pixels from the environment and the natural language instruction as input. The proposed model combines the image and text representations using a Gated-Attention mechanism and learns a policy to execute the natural language instruction using standard reinforcement and imitation learning methods. We show the effectiveness of the proposed model on unseen instructions as well as unseen maps, both quantitatively and qualitatively. We also introduce a novel environment based on a 3D game engine to simulate the challenges of task-oriented language grounding over a rich set of instructions and environment states.