 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom semantics to execution: Integrating action planning with reinforcement learning for robotic tool use
Paper and Code
May 23, 2019
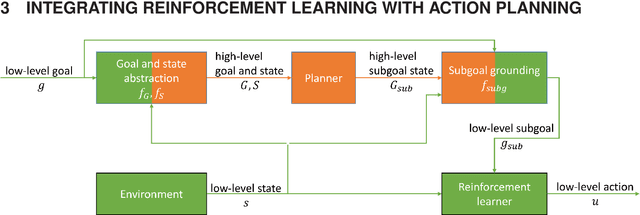
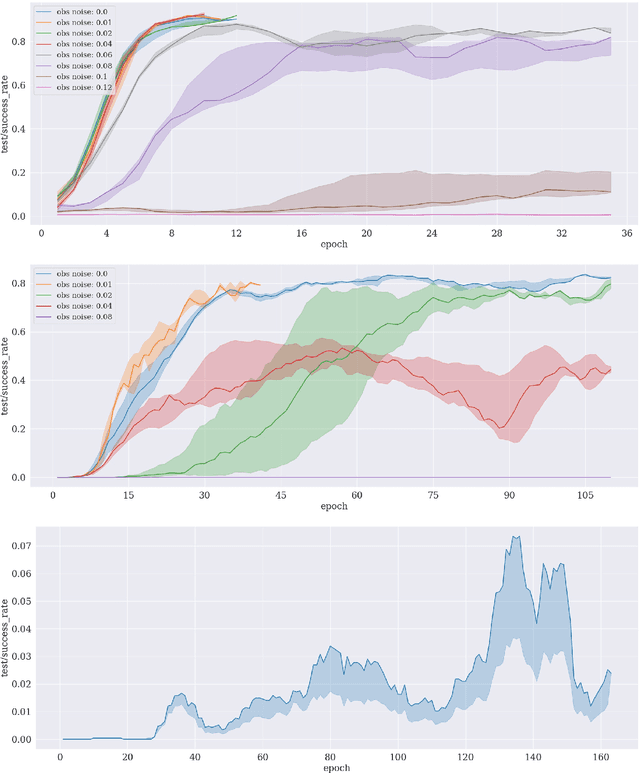

Reinforcement learning is an appropriate and successful method to robustly perform low-level robot control under noisy conditions. Symbolic action planning is useful to resolve causal dependencies and to break a causally complex problem down into a sequence of simpler high-level actions. A problem with the integration of both approaches is that action planning is based on discrete high-level action- and state spaces, whereas reinforcement learning is usually driven by a continuous reward function. However, recent advances in reinforcement learning, specifically, universal value function approximators and hindsight experience replay, have focused on goal-independent methods based on sparse rewards. In this article, we build on these novel methods to facilitate the integration of action planning with reinforcement learning by exploiting the reward-sparsity as a bridge between the high-level and low-level state- and control spaces. As a result, we demonstrate that the integrated neuro-symbolic method is able to solve object manipulation problems that involve tool use and non-trivial causal dependencies under noisy conditions, exploiting both data and knowledge.