 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Representation to Reasoning: Towards both Evidence and Commonsense Reasoning for Video Question-Answering
Paper and Code

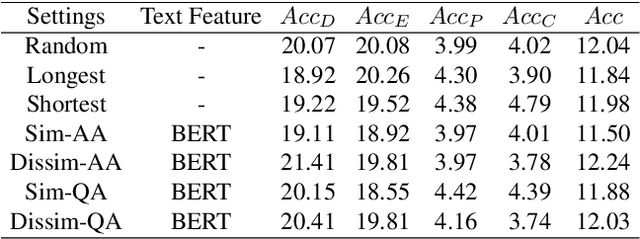

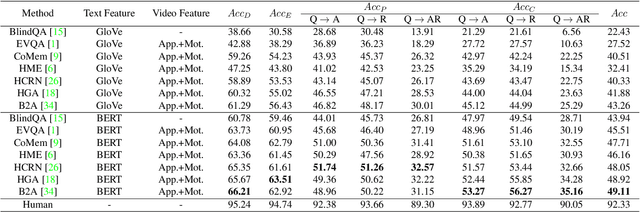
Video understanding has achieved great success in representation learning, such as video caption, video object grounding, and video descriptive question-answer. However, current methods still struggle on video reasoning, including evidence reasoning and commonsense reasoning. To facilitate deeper video understanding towards video reasoning, we present the task of Causal-VidQA, which includes four types of questions ranging from scene description (description) to evidence reasoning (explanation) and commonsense reasoning (prediction and counterfactual). For commonsense reasoning, we set up a two-step solution by answering the question and providing a proper reason. Through extensive experiments on existing VideoQA methods, we find that the state-of-the-art methods are strong in descriptions but weak in reasoning. We hope that Causal-VidQA can guide the research of video understanding from representation learning to deeper reasoning. The dataset and related resources are available at \url{https://github.com/bcmi/Causal-VidQA.git}.