 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFQ-ViT: Fully Quantized Vision Transformer without Retraining
Paper and Code
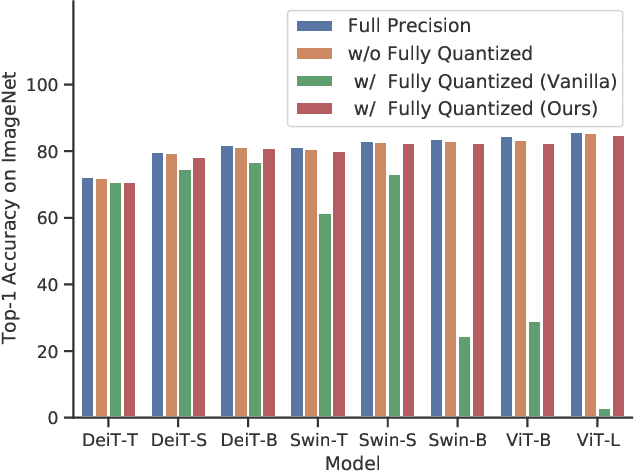


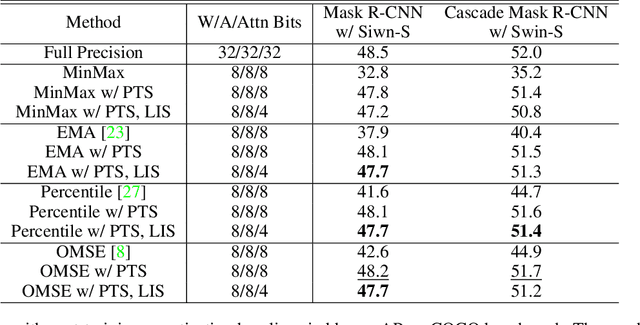
Network quantization significantly reduces model inference complexity and has been widely used in real-world deployments. However, most existing quantization methods have been developed and tested mainly on Convolutional Neural Networks (CNN), and suffer severe degradation when applied to Transformer-based architectures. In this work, we present a systematic method to reduce the performance degradation and inference complexity of Quantized Transformers. In particular, we propose Powers-of-Two Scale (PTS) to deal with the serious inter-channel variation of LayerNorm inputs in a hardware-friendly way. In addition, we propose Log-Int-Softmax (LIS) that can sustain the extreme non-uniform distribution of the attention maps while simplifying inference by using 4-bit quantization and the BitShift operator. Comprehensive experiments on various Transformer-based architectures and benchmarks show that our methods outperform previous works in performance while using even lower bit-width in attention maps. For instance, we reach 85.17% Top-1 accuracy with ViT-L on ImageNet and 51.4 mAP with Cascade Mask R-CNN (Swin-S) on COCO. To our knowledge, we are the first to achieve comparable accuracy degradation (~1%) on fully quantized Vision Transformers. Code is available at https://github.com/linyang-zhh/FQ-ViT.