 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundations of Comparison-Based Hierarchical Clustering
Paper and Code
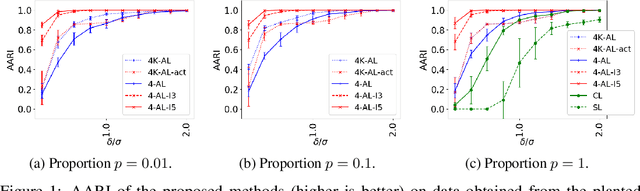
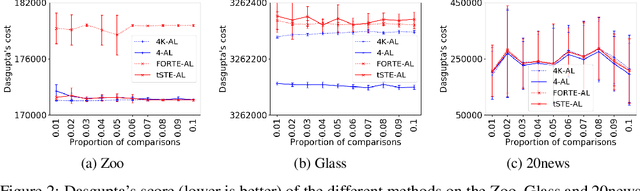
We address the classical problem of hierarchical clustering, but in a framework where one does not have access to a representation of the objects or their pairwise similarities. Instead we assume that only a set of comparisons between objects are available in terms of statements of the form "objects $i$ and $j$ are more similar than objects $k$ and $l$". Such a scenario is commonly encountered in crowdsourcing applications. The focus of this work is to develop comparison-based hierarchical clustering algorithms that do not rely on the principles of ordinal embedding. We propose comparison-based variants of average linkage clustering. We provide statistical guarantees for the proposed methods under a planted partition model for hierarchical clustering. We also empirically demonstrate the performance of the proposed methods on several datasets.