 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForward and Backward Feature Selection for Query Performance Prediction
Paper and Code
Dec 04, 2019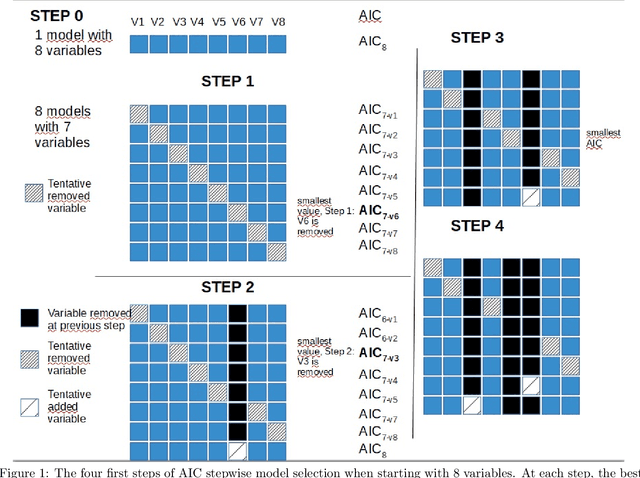
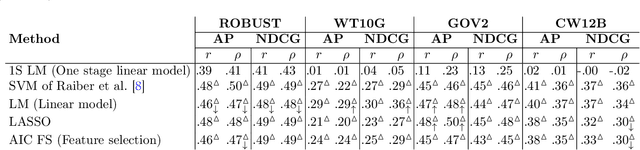
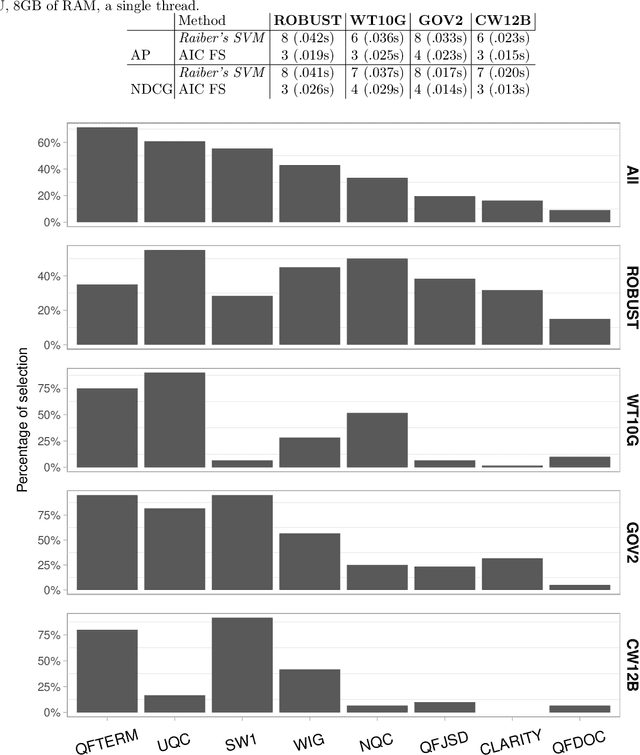
The goal of query performance prediction (QPP) is to automatically estimate the effectiveness of a search result for any given query, without relevance judgements. Post-retrieval features have been shown to be more effective for this task while being more expensive to compute than pre-retrieval features. Combining multiple post-retrieval features is even more effective, but state-of-the-art QPP methods are impossible to interpret because of the black-box nature of the employed machine learning models. However, interpretation is useful for understanding the predictive model and providing more answers about its behavior. Moreover, combining many post-retrieval features is not applicable to real-world cases, since the query running time is of utter importance. In this paper, we investigate a new framework for feature selection in which the trained model explains well the prediction. We introduce a step-wise (forward and backward) model selection approach where different subsets of query features are used to fit different models from which the system selects the best one. We evaluate our approach on four TREC collections using standard QPP features. We also develop two QPP features to address the issue of query-drift in the query feedback setting. We found that: (1) our model based on a limited number of selected features is as good as more complex models for QPP and better than non-selective models; (2) our model is more efficient than complex models during inference time since it requires fewer features; (3) the predictive model is readable and understandable; and (4) one of our new QPP features is consistently selected across different collections, proving its usefulness.