 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormal context reduction in deriving concept hierarchies from corpora using adaptive evolutionary clustering algorithm star
Paper and Code
Jul 10, 2021
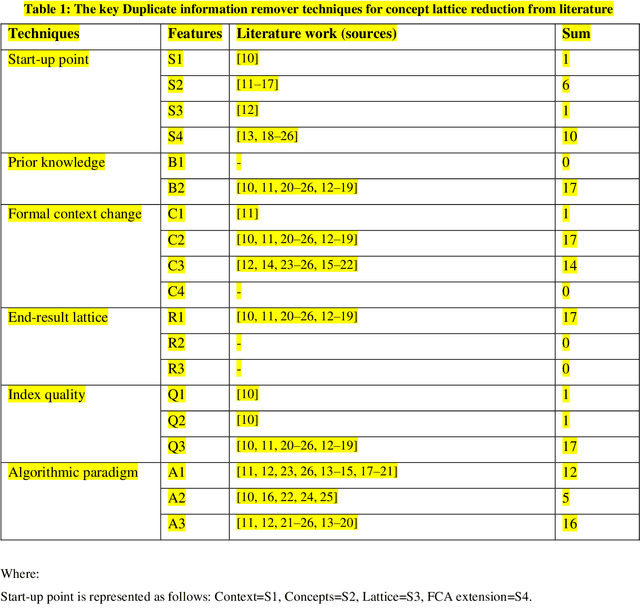


It is beneficial to automate the process of deriving concept hierarchies from corpora since a manual construction of concept hierarchies is typically a time-consuming and resource-intensive process. As such, the overall process of learning concept hierarchies from corpora encompasses a set of steps: parsing the text into sentences, splitting the sentences and then tokenising it. After the lemmatisation step, the pairs are extracted using FCA. However, there might be some uninteresting and erroneous pairs in the formal context. Generating formal context may lead to a time-consuming process, so formal context size reduction is required to remove uninterested and erroneous pairs, taking less time to extract the concept lattice and concept hierarchies accordingly. In this premise, this study aims to propose two frameworks: (1) A framework to review the current process of deriving concept hierarchies from corpus utilising FCA; (2) A framework to decrease the formal contexts ambiguity of the first framework using an adaptive version of ECA*. Experiments are conducted by applying 385 sample corpora from Wikipedia on the two frameworks to examine the reducing size of formal context, which leads to yield concept lattice and concept hierarchy. The resulting lattice of formal context is evaluated to the standard one using concept lattice-invariants. Accordingly, the homomorphic between the two lattices preserves the quality of resulting concept hierarchies by 89% in contrast to the basic ones, and the reduced concept lattice inherits the structural relation of the standard one. The adaptive ECA* is examined against its four counterpart baseline algorithms to measure the execution time on random datasets with different densities (fill ratios). The results show that adaptive ECA* performs concept lattice faster than other mentioned competitive techniques in different fill ratios.