 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForensic Writer Identification Using Microblogging Texts
Paper and Code
Jul 31, 2020
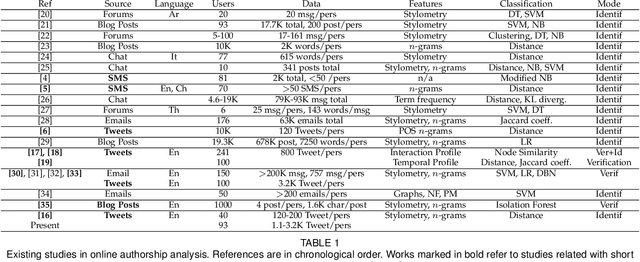
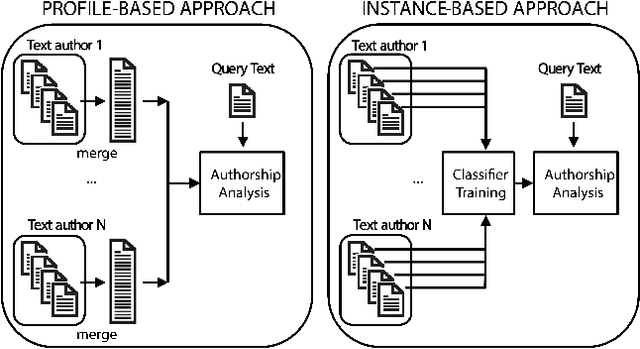
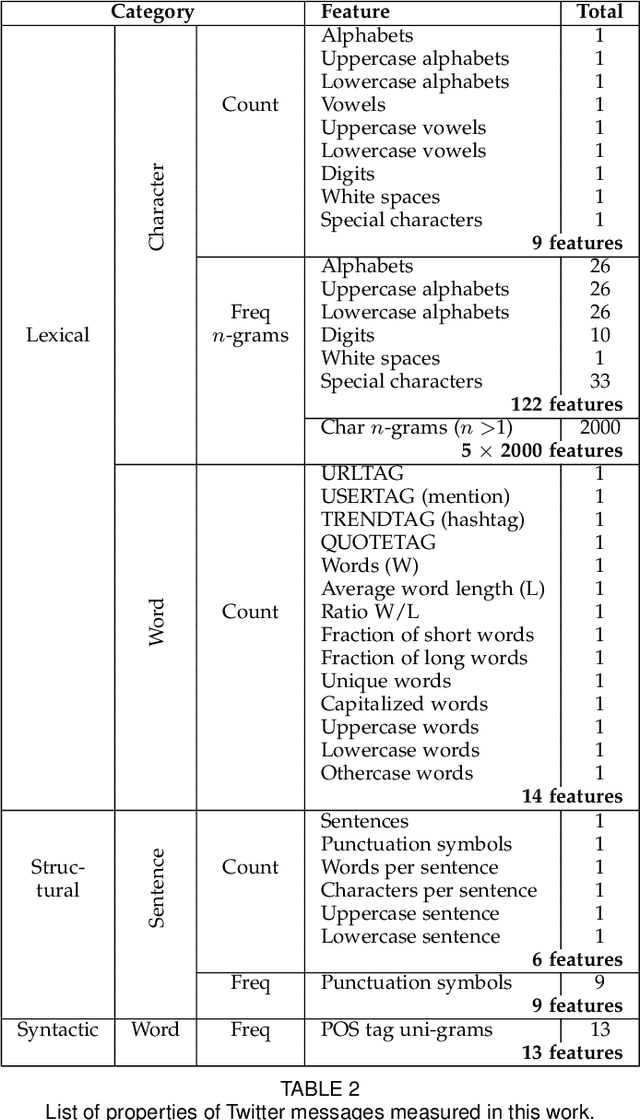
Establishing the authorship of online texts is a fundamental issue to combat several cybercrimes. Unfortunately, some platforms limit the length of the text, making the challenge harder. Here, we aim at identifying the author of Twitter messages limited to 140 characters. We evaluate popular stylometric features, widely used in traditional literary analysis, which capture the writing style at different levels (character, word, and sentence). We use a public database of 93 users, containing 1142 to 3209 Tweets per user. We also evaluate the influence of the number of Tweets per user for enrolment and testing. If the amount is sufficient (>500), a Rank 1 of 97-99% is achieved. If data is scarce (e.g. 20 Tweets for testing), the Rank 1 with the best individual feature method ranges from 54.9% (100 Tweets for enrolment) to 70.6% (1000 Tweets). By combining the available features, a substantial improvement is observed, reaching a Rank 1 of 70% when using 100 Tweets for enrolment and only 20 for testing. With a bigger hit list size, accuracy of the latter case increases to 86.4% (Rank 5) or 95% (Rank 20). This demonstrates the feasibility of identifying writers of digital texts, even with few data available.