 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusing and Diffusion: Bidirectional Attentive Graph Convolutional Networks for Skeleton-based Action Recognition
Paper and Code
Dec 24, 2019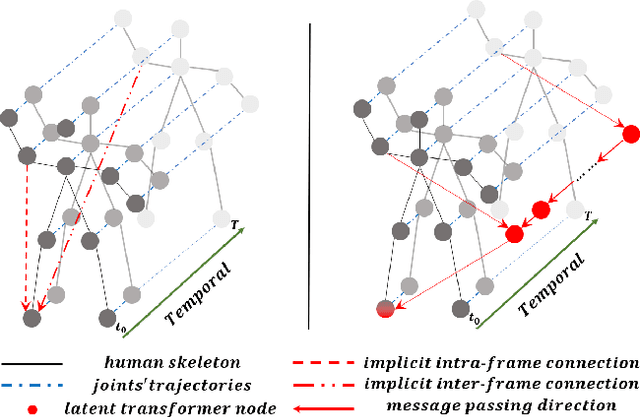



A collection of approaches based on graph convolutional networks have proven success in skeleton-based action recognition by exploring neighborhood information and dense dependencies between intra-frame joints. However, these approaches usually ignore the spatial-temporal global context as well as the local relation between inter-frame and intra-frame. In this paper, we propose a focusing and diffusion mechanism to enhance graph convolutional networks by paying attention to the kinematic dependence of articulated human pose in a frame and their implicit dependencies over frames. In the focusing process, we introduce an attention module to learn a latent node over the intra-frame joints to convey spatial contextual information. In this way, the sparse connections between joints in a frame can be well captured, while the global context over the entire sequence is further captured by these hidden nodes with a bidirectional LSTM. In the diffusing process, the learned spatial-temporal contextual information is passed back to the spatial joints, leading to a bidirectional attentive graph convolutional network (BAGCN) that can facilitate skeleton-based action recognition. Extensive experiments on the challenging NTU RGB+D and Skeleton-Kinetics benchmarks demonstrate the efficacy of our approach.