 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinRL: Deep Reinforcement Learning Framework to Automate Trading in Quantitative Finance
Paper and Code
Nov 07, 2021
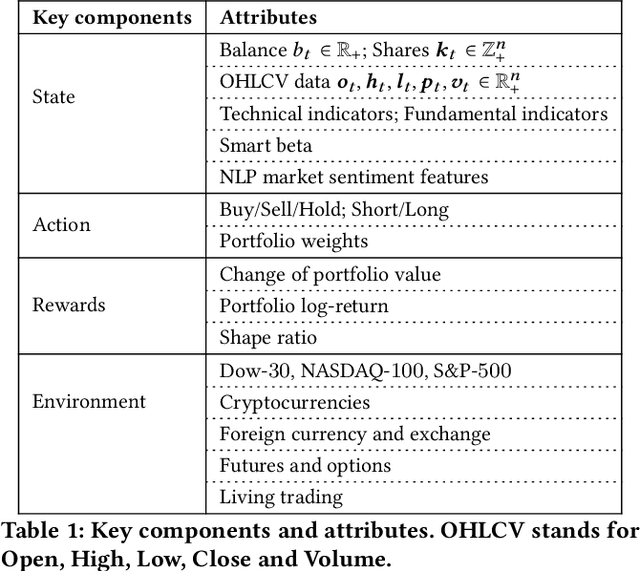
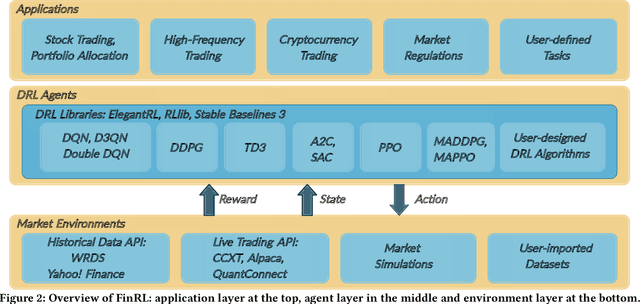

Deep reinforcement learning (DRL) has been envisioned to have a competitive edge in quantitative finance. However, there is a steep development curve for quantitative traders to obtain an agent that automatically positions to win in the market, namely \textit{to decide where to trade, at what price} and \textit{what quantity}, due to the error-prone programming and arduous debugging. In this paper, we present the first open-source framework \textit{FinRL} as a full pipeline to help quantitative traders overcome the steep learning curve. FinRL is featured with simplicity, applicability and extensibility under the key principles, \textit{full-stack framework, customization, reproducibility} and \textit{hands-on tutoring}. Embodied as a three-layer architecture with modular structures, FinRL implements fine-tuned state-of-the-art DRL algorithms and common reward functions, while alleviating the debugging workloads. Thus, we help users pipeline the strategy design at a high turnover rate. At multiple levels of time granularity, FinRL simulates various markets as training environments using historical data and live trading APIs. Being highly extensible, FinRL reserves a set of user-import interfaces and incorporates trading constraints such as market friction, market liquidity and investor's risk-aversion. Moreover, serving as practitioners' stepping stones, typical trading tasks are provided as step-by-step tutorials, e.g., stock trading, portfolio allocation, cryptocurrency trading, etc.