 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Time Complexity of Online Primal-Dual Natural Actor-Critic Algorithm for Constrained Markov Decision Processes
Paper and Code
Oct 21, 2021
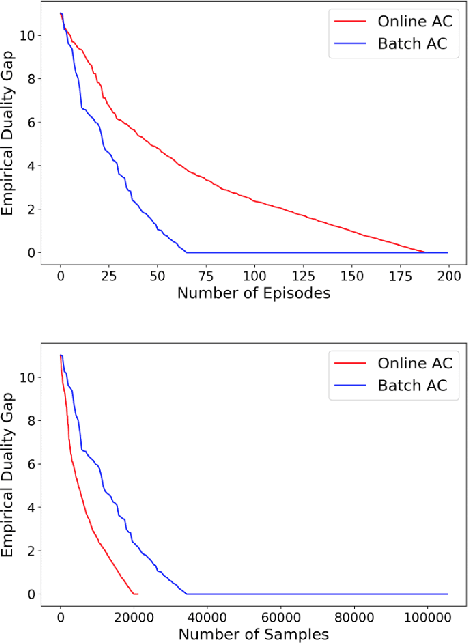
We consider a discounted cost constrained Markov decision process (CMDP) policy optimization problem, in which an agent seeks to maximize a discounted cumulative reward subject to a number of constraints on discounted cumulative utilities. To solve this constrained optimization program, we study an online actor-critic variant of a classic primal-dual method where the gradients of both the primal and dual functions are estimated using samples from a single trajectory generated by the underlying time-varying Markov processes. This online primal-dual natural actor-critic algorithm maintains and iteratively updates three variables: a dual variable (or Lagrangian multiplier), a primal variable (or actor), and a critic variable used to estimate the gradients of both primal and dual variables. These variables are updated simultaneously but on different time scales (using different step sizes) and they are all intertwined with each other. Our main contribution is to derive a finite-time analysis for the convergence of this algorithm to the global optimum of a CMDP problem. Specifically, we show that with a proper choice of step sizes the optimality gap and constraint violation converge to zero in expectation at a rate $\mathcal{O}(1/K^{1/6})$, where K is the number of iterations. To our knowledge, this paper is the first to study the finite-time complexity of an online primal-dual actor-critic method for solving a CMDP problem. We also validate the effectiveness of this algorithm through numerical simulations.