 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Sample Analysis of Off-Policy Natural Actor-Critic with Linear Function Approximation
Paper and Code
May 26, 2021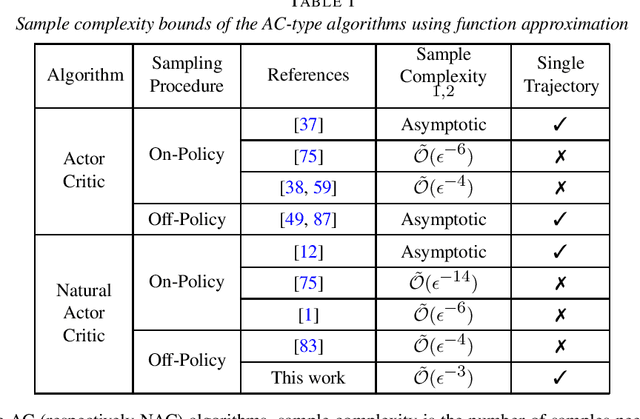
In this paper, we develop a novel variant of off-policy natural actor-critic algorithm with linear function approximation and we establish a sample complexity of $\mathcal{O}(\epsilon^{-3})$, outperforming all the previously known convergence bounds of such algorithms. In order to overcome the divergence due to deadly triad in off-policy policy evaluation under function approximation, we develop a critic that employs $n$-step TD-learning algorithm with a properly chosen $n$. We present finite-sample convergence bounds on this critic under both constant and diminishing step sizes, which are of independent interest. Furthermore, we develop a variant of natural policy gradient under function approximation, with an improved convergence rate of $\mathcal{O}(1/T)$ after $T$ iterations. Combining the finite sample error bounds of actor and the critic, we obtain the $\mathcal{O}(\epsilon^{-3})$ sample complexity. We derive our sample complexity bounds solely based on the assumption that the behavior policy sufficiently explores all the states and actions, which is a much lighter assumption compared to the related literature.