 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning BERT for Automatic ADME Semantic Labeling in FDA Drug Labeling to Enhance Product-Specific Guidance Assessment
Paper and Code
Jul 25, 2022

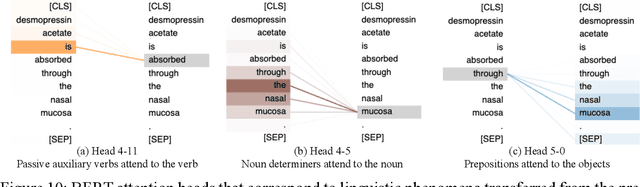
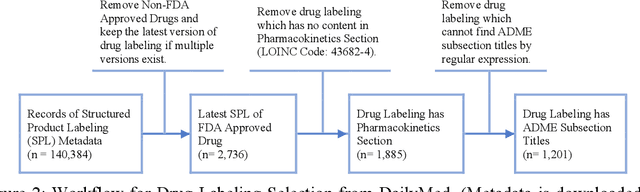
Product-specific guidances (PSGs) recommended by the United States Food and Drug Administration (FDA) are instrumental to promote and guide generic drug product development. To assess a PSG, the FDA assessor needs to take extensive time and effort to manually retrieve supportive drug information of absorption, distribution, metabolism, and excretion (ADME) from the reference listed drug labeling. In this work, we leveraged the state-of-the-art pre-trained language models to automatically label the ADME paragraphs in the pharmacokinetics section from the FDA-approved drug labeling to facilitate PSG assessment. We applied a transfer learning approach by fine-tuning the pre-trained Bidirectional Encoder Representations from Transformers (BERT) model to develop a novel application of ADME semantic labeling, which can automatically retrieve ADME paragraphs from drug labeling instead of manual work. We demonstrated that fine-tuning the pre-trained BERT model can outperform the conventional machine learning techniques, achieving up to 11.6% absolute F1 improvement. To our knowledge, we were the first to successfully apply BERT to solve the ADME semantic labeling task. We further assessed the relative contribution of pre-training and fine-tuning to the overall performance of the BERT model in the ADME semantic labeling task using a series of analysis methods such as attention similarity and layer-based ablations. Our analysis revealed that the information learned via fine-tuning is focused on task-specific knowledge in the top layers of the BERT, whereas the benefit from the pre-trained BERT model is from the bottom layers.