 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Already Debunked Narratives via Multistage Retrieval: Enabling Cross-Lingual, Cross-Dataset and Zero-Shot Learning
Paper and Code
Aug 10, 2023

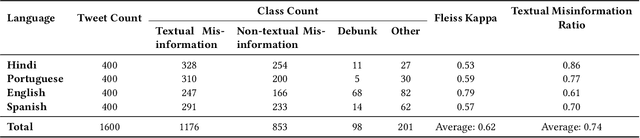
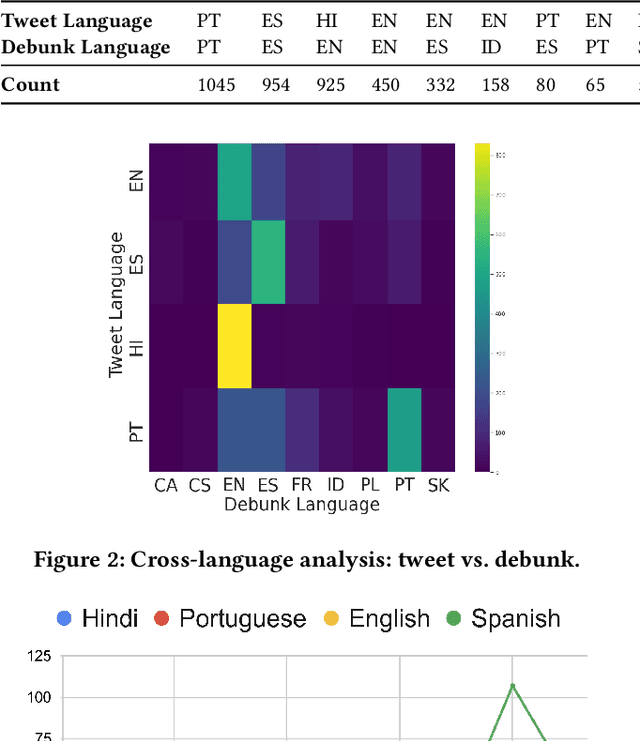
The task of retrieving already debunked narratives aims to detect stories that have already been fact-checked. The successful detection of claims that have already been debunked not only reduces the manual efforts of professional fact-checkers but can also contribute to slowing the spread of misinformation. Mainly due to the lack of readily available data, this is an understudied problem, particularly when considering the cross-lingual task, i.e. the retrieval of fact-checking articles in a language different from the language of the online post being checked. This paper fills this gap by (i) creating a novel dataset to enable research on cross-lingual retrieval of already debunked narratives, using tweets as queries to a database of fact-checking articles; (ii) presenting an extensive experiment to benchmark fine-tuned and off-the-shelf multilingual pre-trained Transformer models for this task; and (iii) proposing a novel multistage framework that divides this cross-lingual debunk retrieval task into refinement and re-ranking stages. Results show that the task of cross-lingual retrieval of already debunked narratives is challenging and off-the-shelf Transformer models fail to outperform a strong lexical-based baseline (BM25). Nevertheless, our multistage retrieval framework is robust, outperforming BM25 in most scenarios and enabling cross-domain and zero-shot learning, without significantly harming the model's performance.