 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilling the Image Information Gap for VQA: Prompting Large Language Models to Proactively Ask Questions
Paper and Code


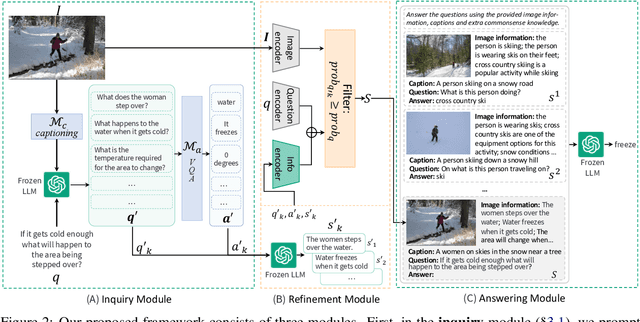

Large Language Models (LLMs) demonstrate impressive reasoning ability and the maintenance of world knowledge not only in natural language tasks, but also in some vision-language tasks such as open-domain knowledge-based visual question answering (OK-VQA). As images are invisible to LLMs, researchers convert images to text to engage LLMs into the visual question reasoning procedure. This leads to discrepancies between images and their textual representations presented to LLMs, which consequently impedes final reasoning performance. To fill the information gap and better leverage the reasoning capability, we design a framework that enables LLMs to proactively ask relevant questions to unveil more details in the image, along with filters for refining the generated information. We validate our idea on OK-VQA and A-OKVQA. Our method continuously boosts the performance of baselines methods by an average gain of 2.15% on OK-VQA, and achieves consistent improvements across different LLMs.