 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFighting with the Sparsity of Synonymy Dictionaries
Paper and Code
Aug 30, 2017
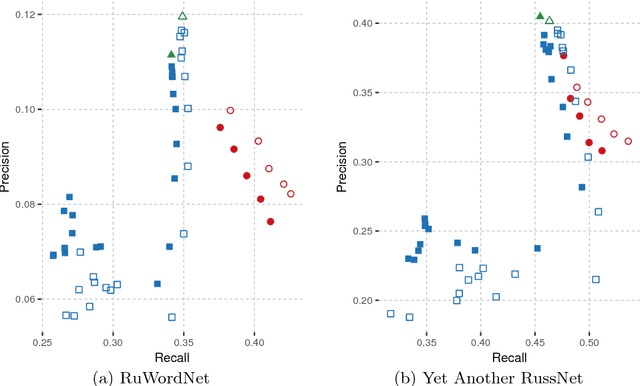

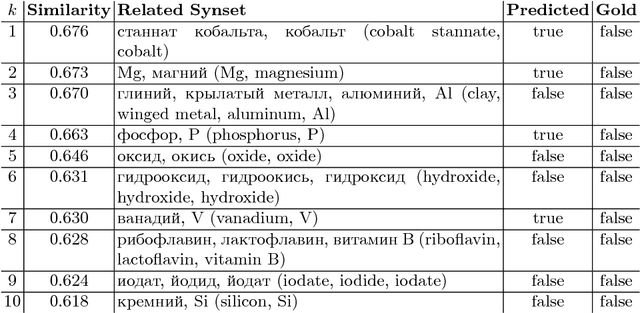
Graph-based synset induction methods, such as MaxMax and Watset, induce synsets by performing a global clustering of a synonymy graph. However, such methods are sensitive to the structure of the input synonymy graph: sparseness of the input dictionary can substantially reduce the quality of the extracted synsets. In this paper, we propose two different approaches designed to alleviate the incompleteness of the input dictionaries. The first one performs a pre-processing of the graph by adding missing edges, while the second one performs a post-processing by merging similar synset clusters. We evaluate these approaches on two datasets for the Russian language and discuss their impact on the performance of synset induction methods. Finally, we perform an extensive error analysis of each approach and discuss prominent alternative methods for coping with the problem of the sparsity of the synonymy dictionaries.