 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Multi-Task Learning of Linear Invariant Features with Meta Subspace Pursuit
Paper and Code
Sep 04, 2024
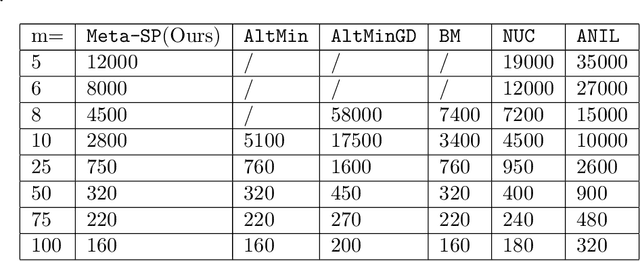

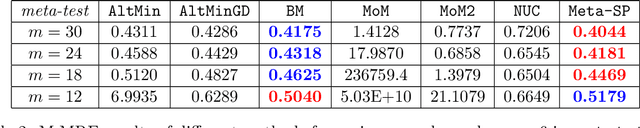
Data scarcity poses a serious threat to modern machine learning and artificial intelligence, as their practical success typically relies on the availability of big datasets. One effective strategy to mitigate the issue of insufficient data is to first harness information from other data sources possessing certain similarities in the study design stage, and then employ the multi-task or meta learning framework in the analysis stage. In this paper, we focus on multi-task (or multi-source) linear models whose coefficients across tasks share an invariant low-rank component, a popular structural assumption considered in the recent multi-task or meta learning literature. Under this assumption, we propose a new algorithm, called Meta Subspace Pursuit (abbreviated as Meta-SP), that provably learns this invariant subspace shared by different tasks. Under this stylized setup for multi-task or meta learning, we establish both the algorithmic and statistical guarantees of the proposed method. Extensive numerical experiments are conducted, comparing Meta-SP against several competing methods, including popular, off-the-shelf model-agnostic meta learning algorithms such as ANIL. These experiments demonstrate that Meta-SP achieves superior performance over the competing methods in various aspects.