 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeedback-efficient Active Preference Learning for Socially Aware Robot Navigation
Paper and Code
Jan 11, 2022
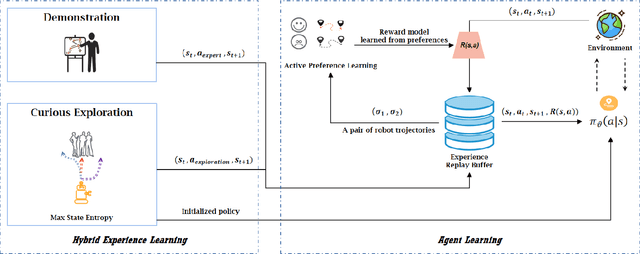
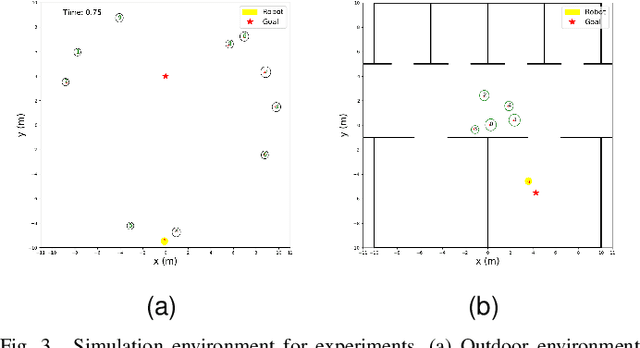
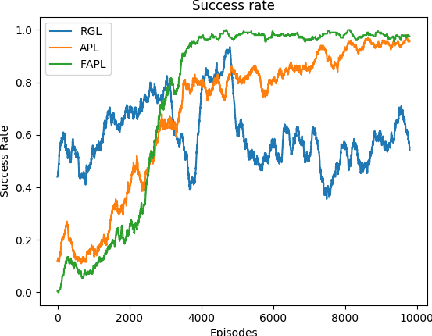
Socially aware robot navigation, where a robot is required to optimize its trajectories to maintain a comfortable and compliant spatial interaction with humans in addition to the objective of reaching the goal without collisions, is a fundamental yet challenging task for robots navigating in the context of human-robot interaction. Much as existing learning-based methods have achieved a better performance than previous model-based ones, they still have some drawbacks: the reinforcement learning approaches, which reply on a handcrafted reward for optimization, are unlikely to emulate social compliance comprehensively and can lead to reward exploitation problems; the inverse reinforcement learning approaches, which learn a policy via human demonstrations, suffer from expensive and partial samples, and need extensive feature engineering to be reasonable. In this paper, we propose FAPL, a feedback-efficient interactive reinforcement learning approach that distills human preference and comfort into a reward model, which serves as a teacher to guide the agent to explore latent aspects of social compliance. Hybrid experience and off-policy learning are introduced to improve the efficiency of samples and human feedback. Extensive simulation experiments demonstrate the advantages of FAPL quantitatively and qualitatively.