 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Split BERT for Heterogeneous Text Classification
Paper and Code
May 26, 2022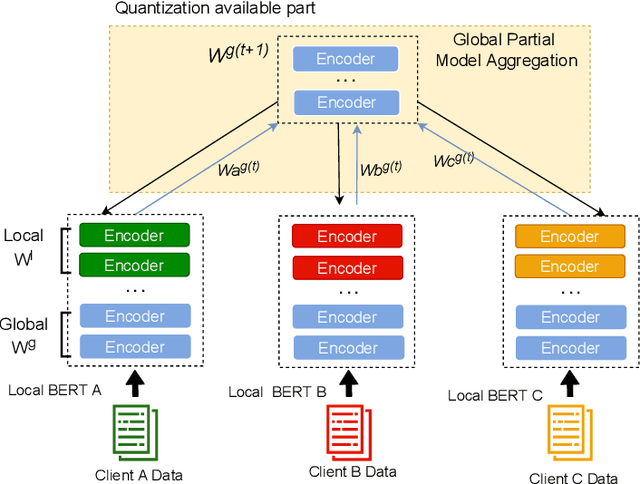
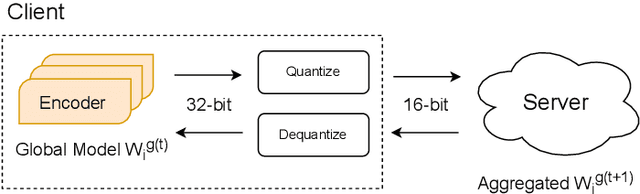
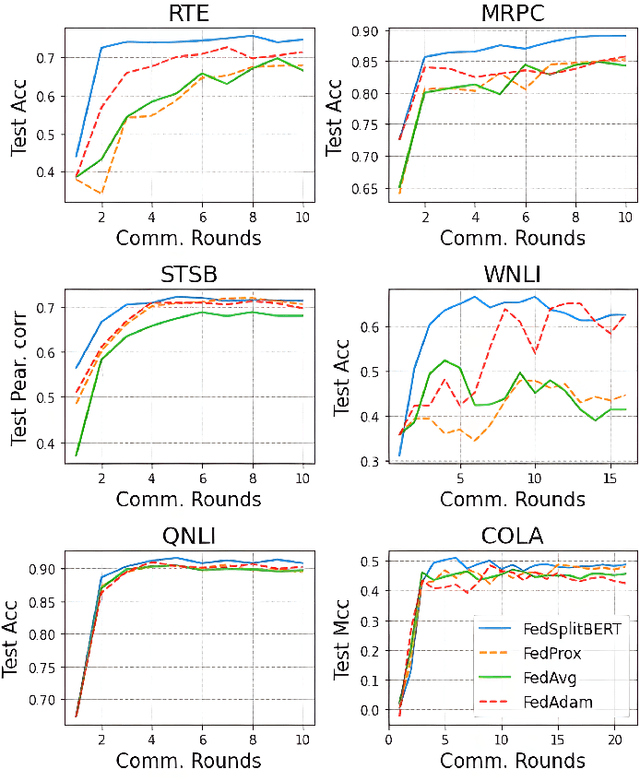
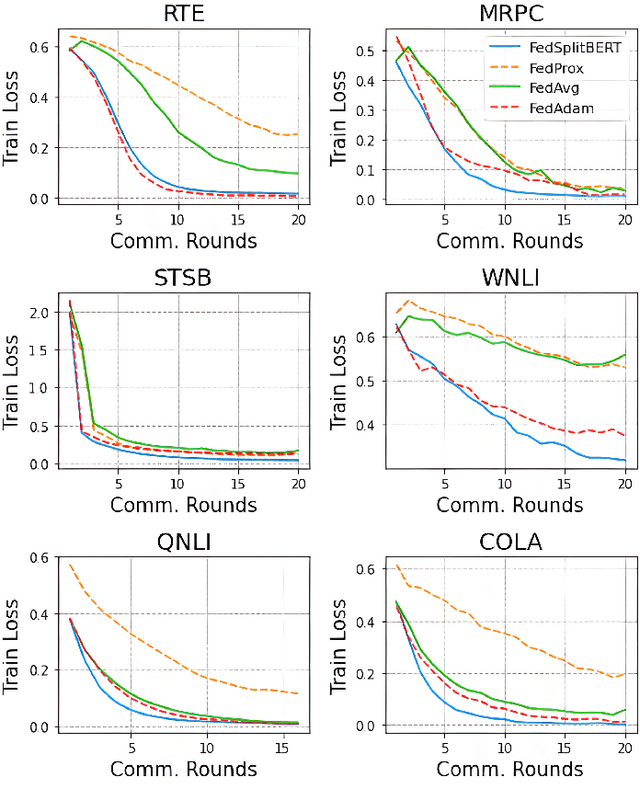
Pre-trained BERT models have achieved impressive performance in many natural language processing (NLP) tasks. However, in many real-world situations, textual data are usually decentralized over many clients and unable to be uploaded to a central server due to privacy protection and regulations. Federated learning (FL) enables multiple clients collaboratively to train a global model while keeping the local data privacy. A few researches have investigated BERT in federated learning setting, but the problem of performance loss caused by heterogeneous (e.g., non-IID) data over clients remain under-explored. To address this issue, we propose a framework, FedSplitBERT, which handles heterogeneous data and decreases the communication cost by splitting the BERT encoder layers into local part and global part. The local part parameters are trained by the local client only while the global part parameters are trained by aggregating gradients of multiple clients. Due to the sheer size of BERT, we explore a quantization method to further reduce the communication cost with minimal performance loss. Our framework is ready-to-use and compatible to many existing federated learning algorithms, including FedAvg, FedProx and FedAdam. Our experiments verify the effectiveness of the proposed framework, which outperforms baseline methods by a significant margin, while FedSplitBERT with quantization can reduce the communication cost by $11.9\times$.