 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Semi-Supervised Learning with Class Distribution Mismatch
Paper and Code
Oct 29, 2021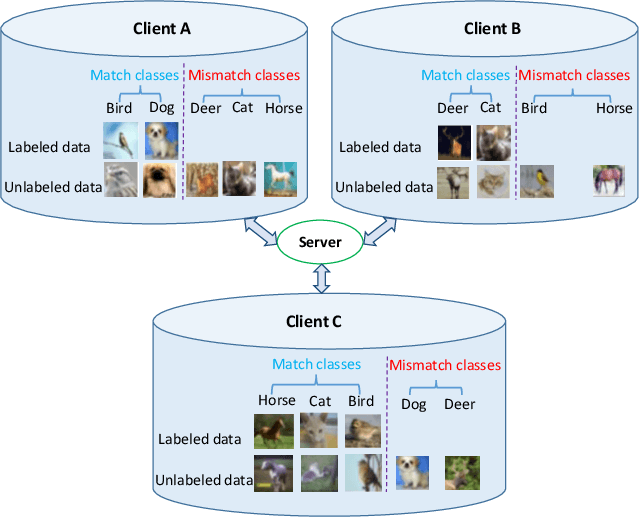



Many existing federated learning (FL) algorithms are designed for supervised learning tasks, assuming that the local data owned by the clients are well labeled. However, in many practical situations, it could be difficult and expensive to acquire complete data labels. Federated semi-supervised learning (Fed-SSL) is an attractive solution for fully utilizing both labeled and unlabeled data. Similar to that encountered in federated supervised learning, class distribution of labeled/unlabeled data could be non-i.i.d. among clients. Besides, in each client, the class distribution of labeled data may be distinct from that of unlabeled data. Unfortunately, both can severely jeopardize the FL performance. To address such challenging issues, we introduce two proper regularization terms that can effectively alleviate the class distribution mismatch problem in Fed-SSL. In addition, to overcome the non-i.i.d. data, we leverage the variance reduction and normalized averaging techniques to develop a novel Fed-SSL algorithm. Theoretically, we prove that the proposed method has a convergence rate of $\mathcal{O}(1/\sqrt{T})$, where $T$ is the number of communication rounds, even when the data distribution are non-i.i.d. among clients. To the best of our knowledge, it is the first formal convergence result for Fed-SSL problems. Numerical experiments based on MNIST data and CIFAR-10 data show that the proposed method can greatly improve the classification accuracy compared to baselines.