 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Nonconvex Sparse Learning
Paper and Code
Dec 31, 2020
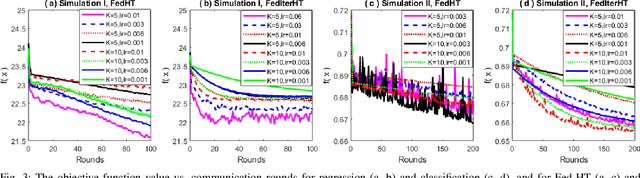
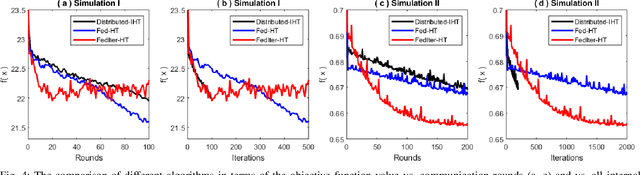
Nonconvex sparse learning plays an essential role in many areas, such as signal processing and deep network compression. Iterative hard thresholding (IHT) methods are the state-of-the-art for nonconvex sparse learning due to their capability of recovering true support and scalability with large datasets. Theoretical analysis of IHT is currently based on centralized IID data. In realistic large-scale situations, however, data are distributed, hardly IID, and private to local edge computing devices. It is thus necessary to examine the property of IHT in federated settings, which update in parallel on local devices and communicate with a central server only once in a while without sharing local data. In this paper, we propose two IHT methods: Federated Hard Thresholding (Fed-HT) and Federated Iterative Hard Thresholding (FedIter-HT). We prove that both algorithms enjoy a linear convergence rate and have strong guarantees to recover the optimal sparse estimator, similar to traditional IHT methods, but now with decentralized non-IID data. Empirical results demonstrate that the Fed-HT and FedIter-HT outperform their competitor - a distributed IHT, in terms of decreasing the objective values with lower requirements on communication rounds and bandwidth.