 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning of Molecular Properties in a Heterogeneous Setting
Paper and Code
Sep 15, 2021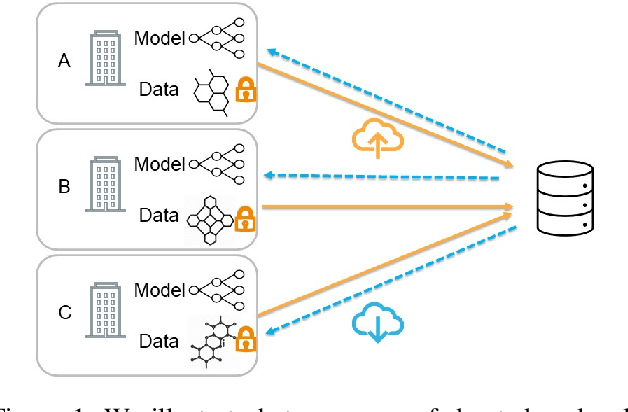
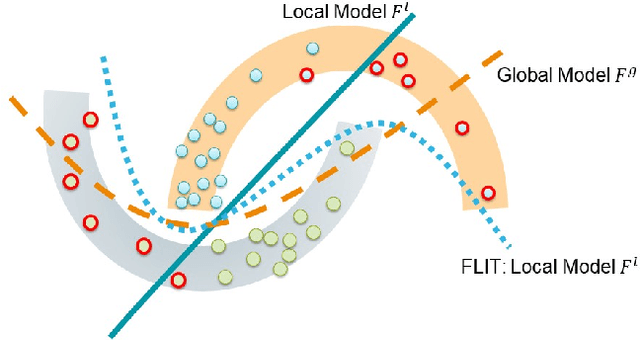
Chemistry research has both high material and computational costs to conduct experiments. Institutions thus consider chemical data to be valuable and there have been few efforts to construct large public datasets for machine learning. Another challenge is that different intuitions are interested in different classes of molecules, creating heterogeneous data that cannot be easily joined by conventional distributed training. In this work, we introduce federated heterogeneous molecular learning to address these challenges. Federated learning allows end-users to build a global model collaboratively while preserving the training data distributed over isolated clients. Due to the lack of related research, we first simulate a federated heterogeneous benchmark called FedChem. FedChem is constructed by jointly performing scaffold splitting and Latent Dirichlet Allocation on existing datasets. Our results on FedChem show that significant learning challenges arise when working with heterogeneous molecules. We then propose a method to alleviate the problem, namely Federated Learning by Instance reweighTing (FLIT). FLIT can align the local training across heterogeneous clients by improving the performance for uncertain samples. Comprehensive experiments conducted on our new benchmark FedChem validate the advantages of this method over other federated learning schemes. FedChem should enable a new type of collaboration for improving AI in chemistry that mitigates concerns about valuable chemical data.